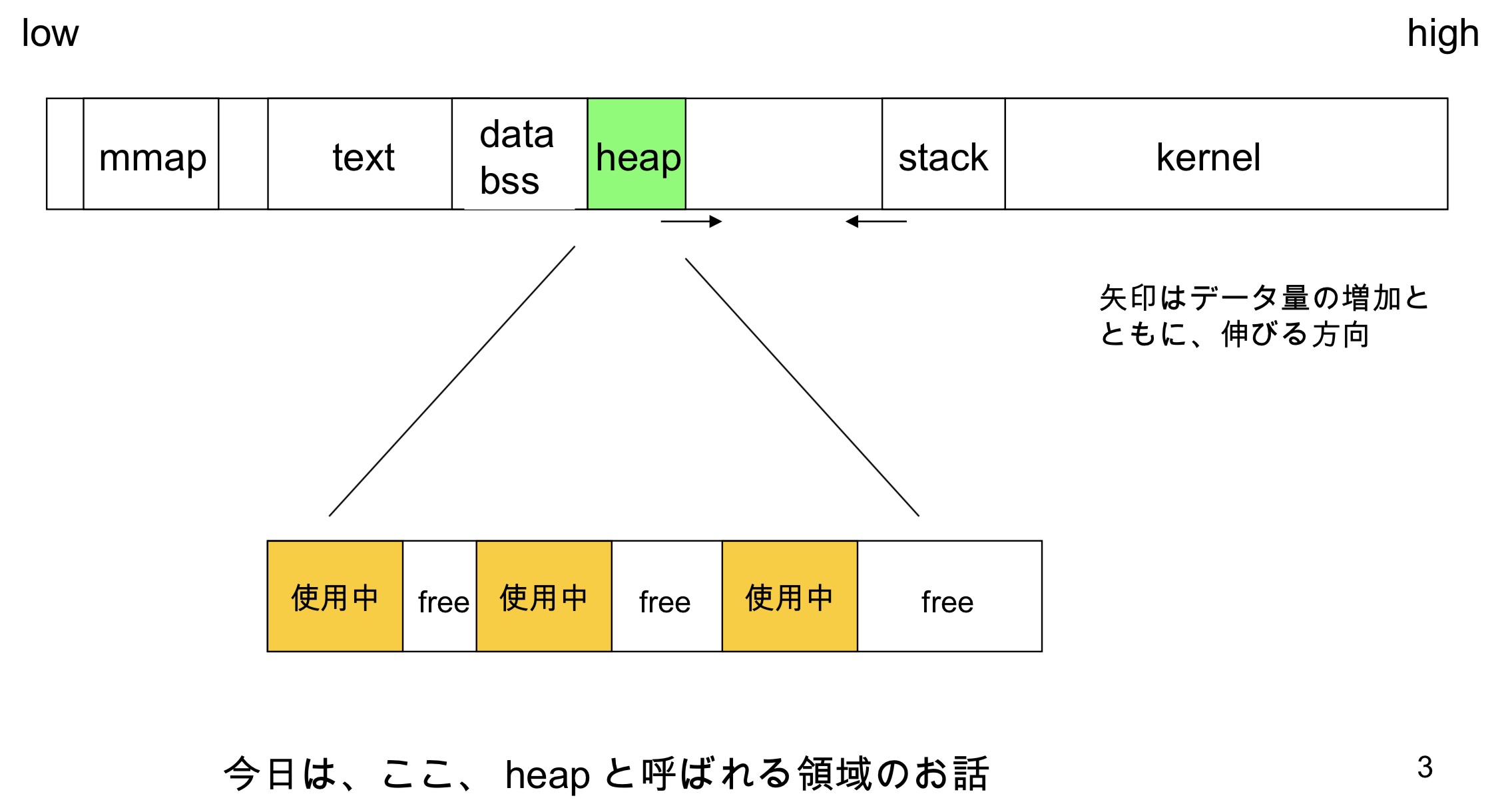
Linux中进程地址空间模型
古典的malloc
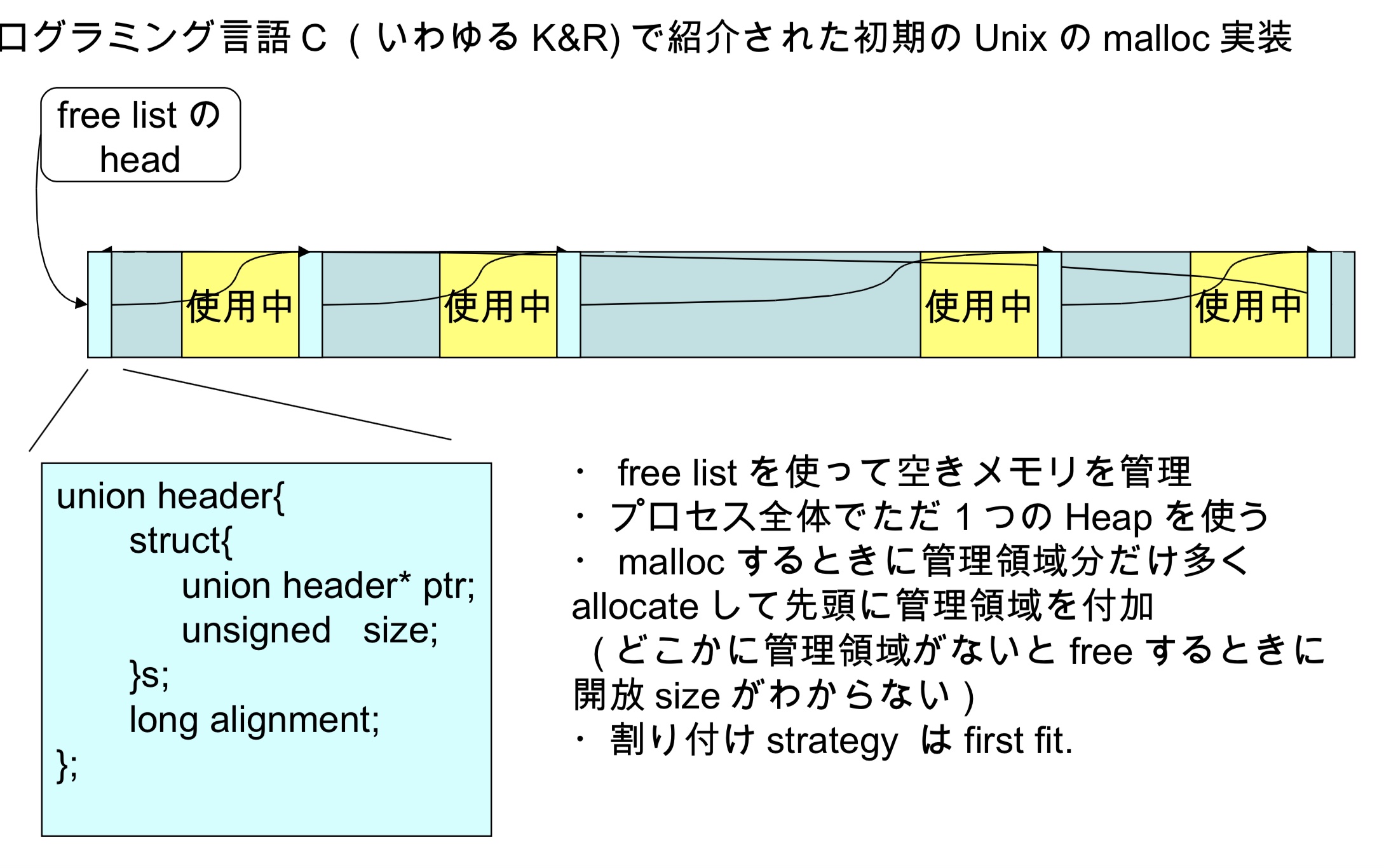
- 使用free list来管理空闲内存
- 整个进程只使用一个heap
- 使用malloc的时候,管理区域会使用多个allocate,并且将头部追加到管理区域(如果某个地方没有管理区域,那么在free的时候将不知道需要释放的size)
- 分配策略是first fit
malloc的算法
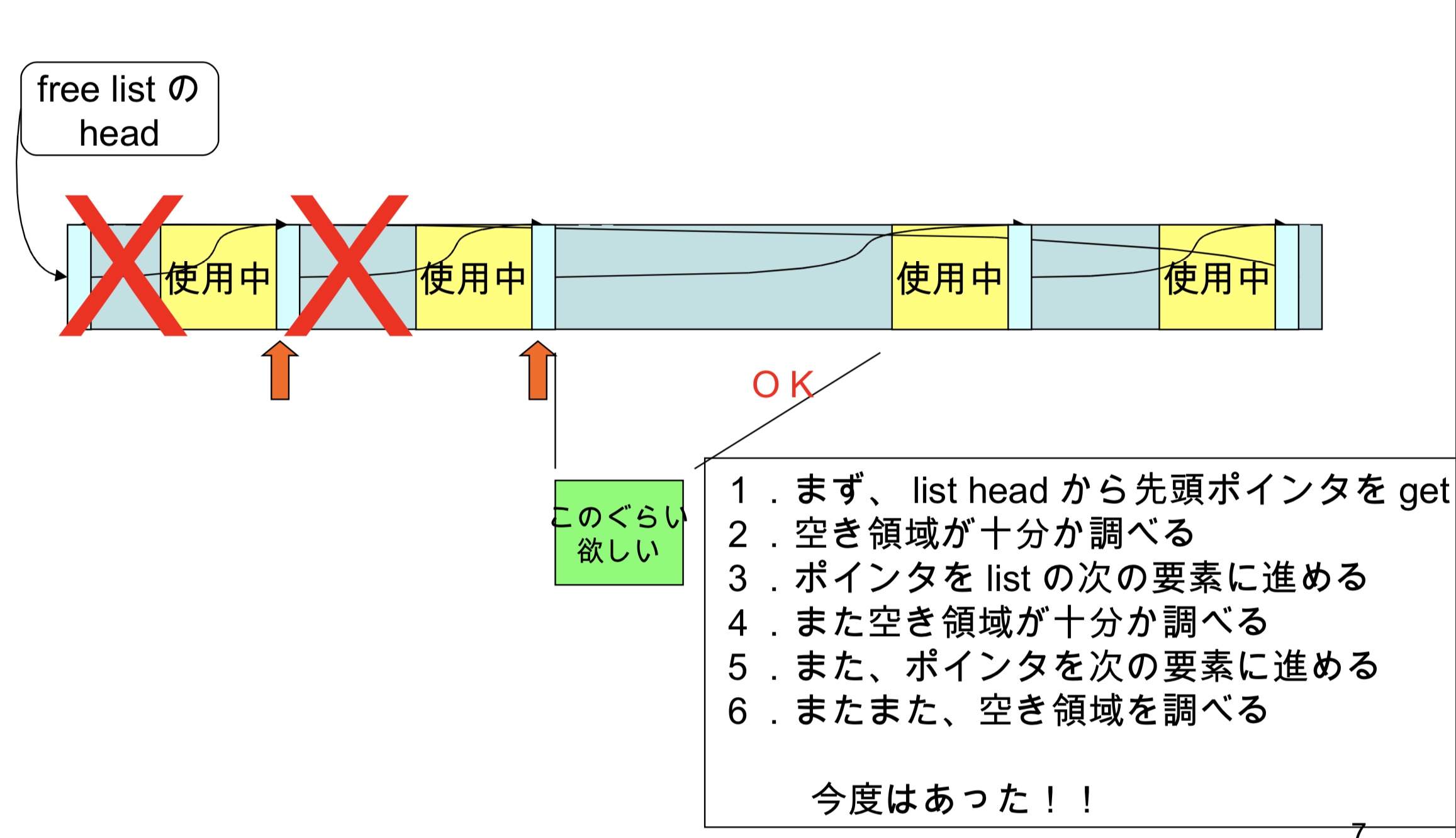
- 首先,从列表头获取头指针
- 检查可用空间是否足够
- 指针前进到列表的下一个节点
- 检查可用空间是否足够
- 再次将指针前进到列表的下一个节点
- 再次,检查可用空间
此时,满足条件
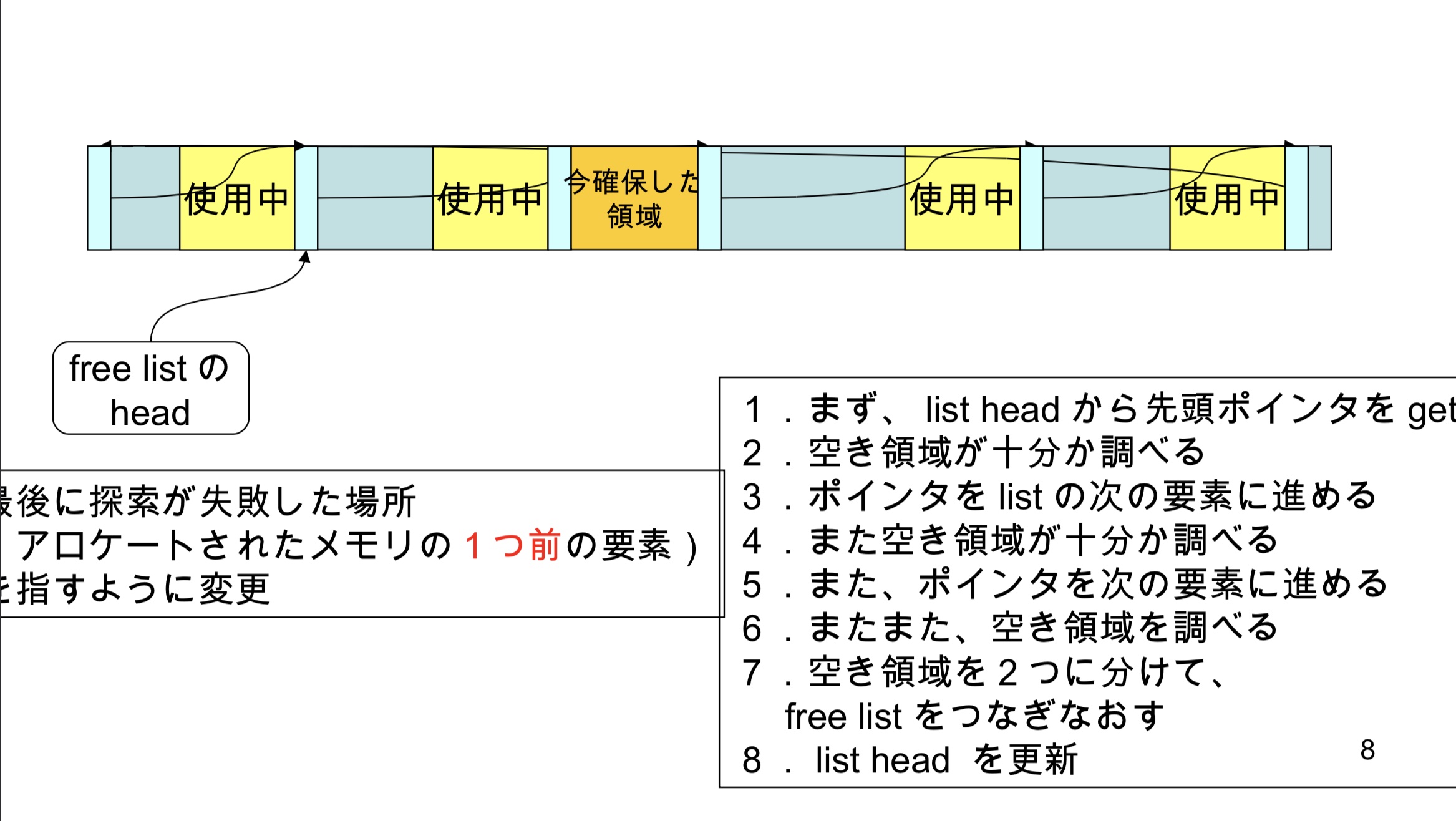
- 将空闲区域分成两部分
- 更新list head
此时first list的head:
最终搜索失败的地方(分配内存的前一个节点)
实际情况
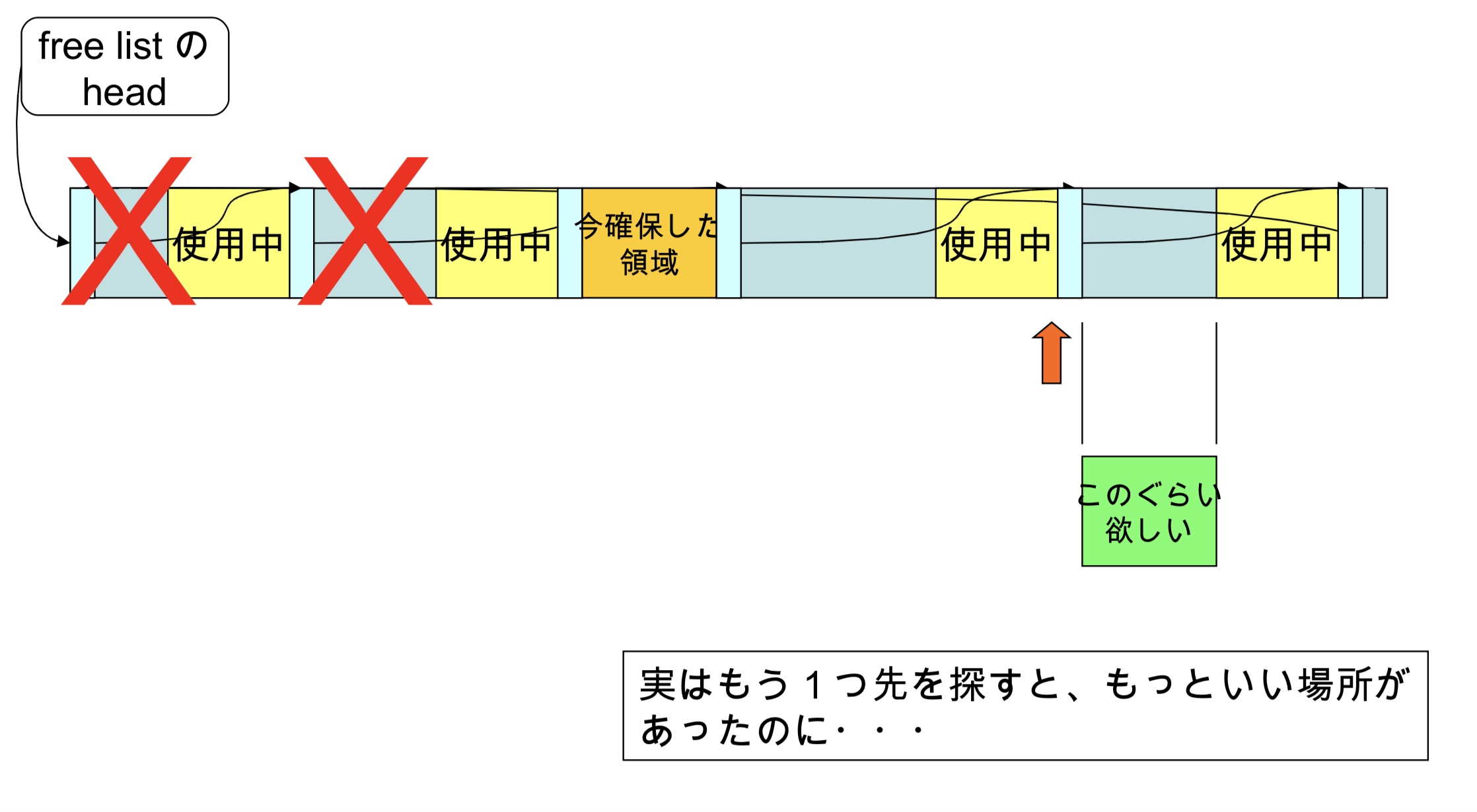
实际上会寻找一个更合适的区域
free的算法
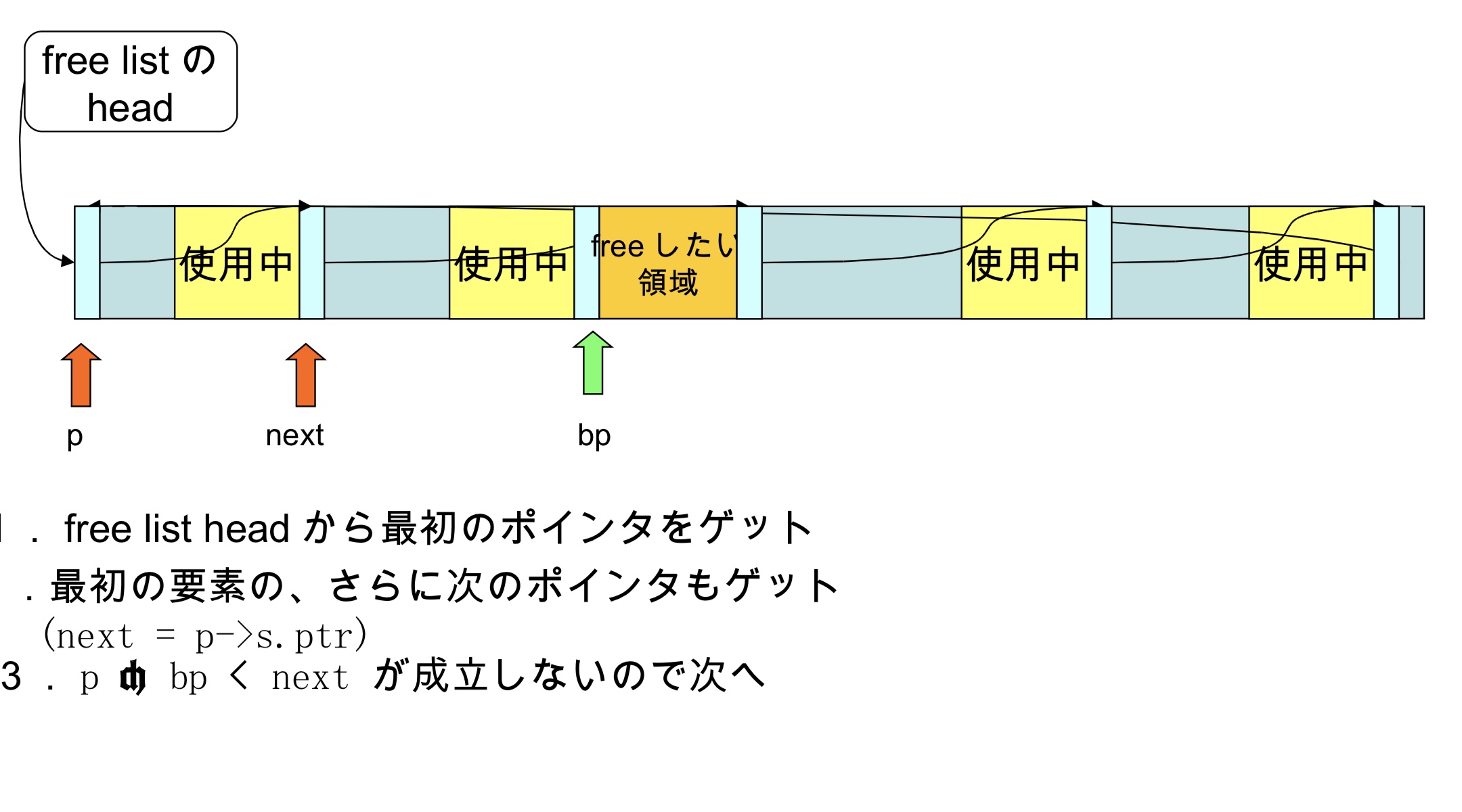
- 从free list head获取第一个指针
- 获取第一个节点的下一个指针(next = p->s.ptr)
- 由于p<bp<next 不成立,进入下一步
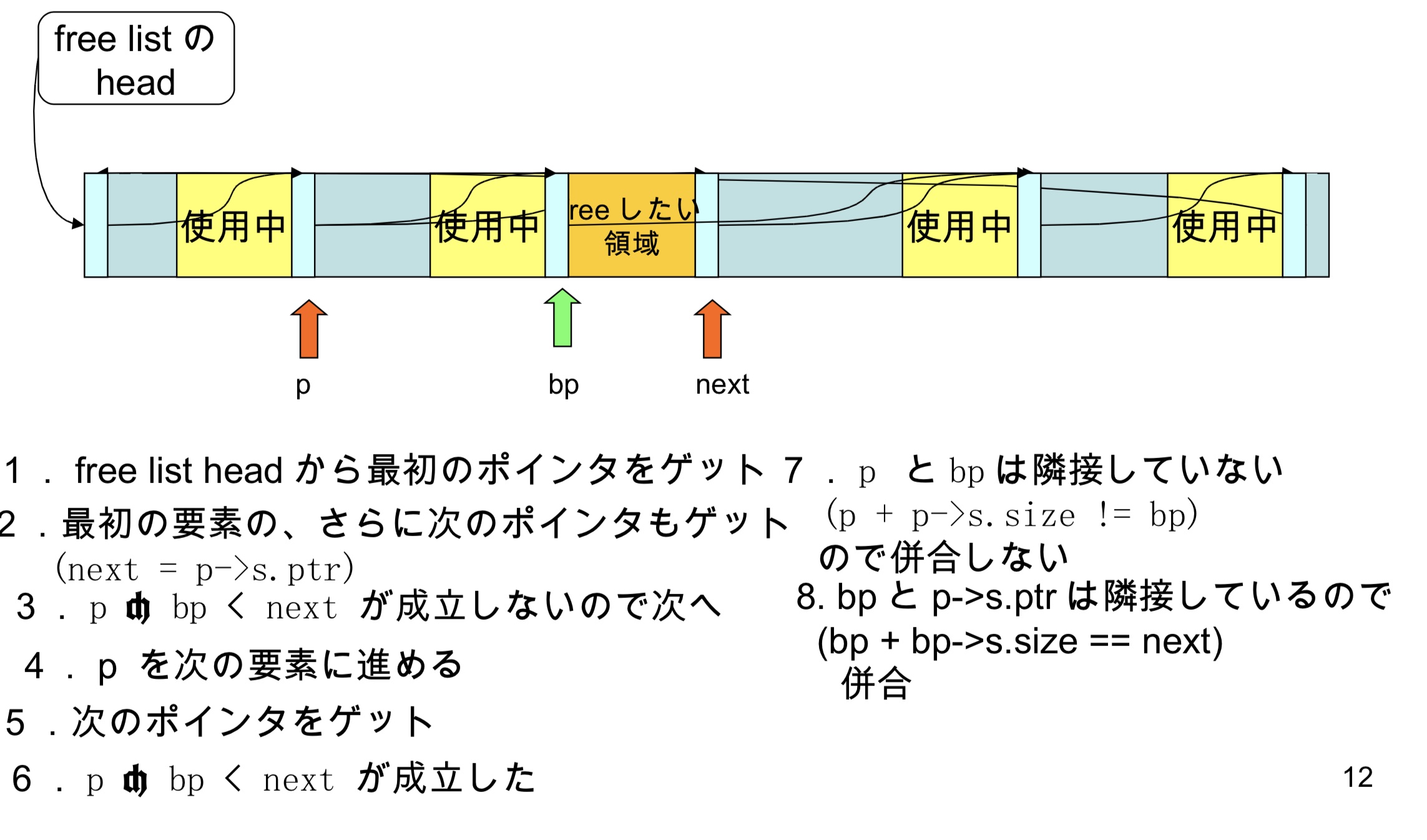
- p前进到下一个节点
- 获取下一个指针
- p<bp<next成立
- p和bp不相邻( p + p->size != bp)
- 因为bp和p->s.ptr相邻(bp + bp->s.size == next),合并
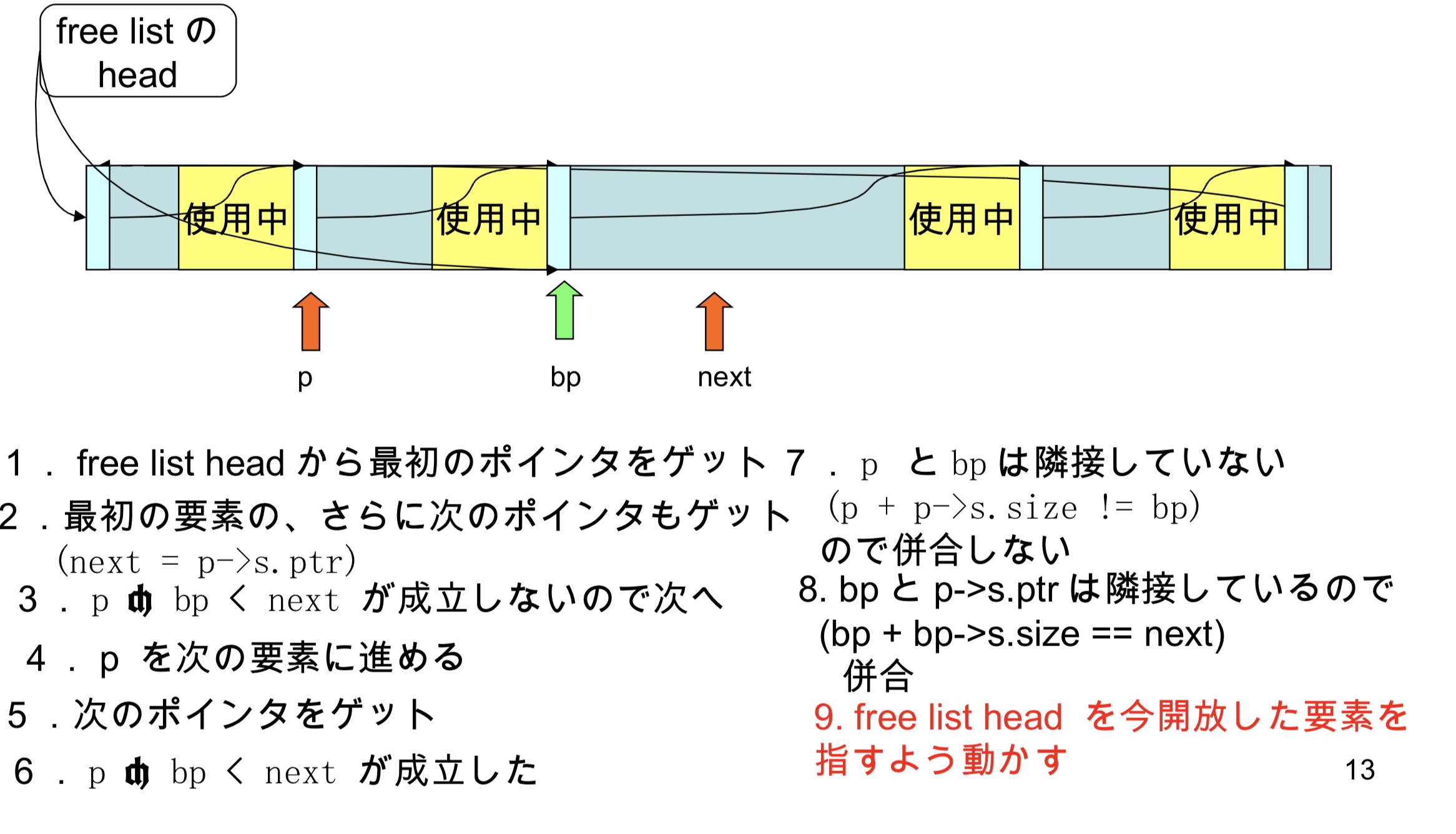
- free list head现在指向释放掉的节点
