回顾K&R free
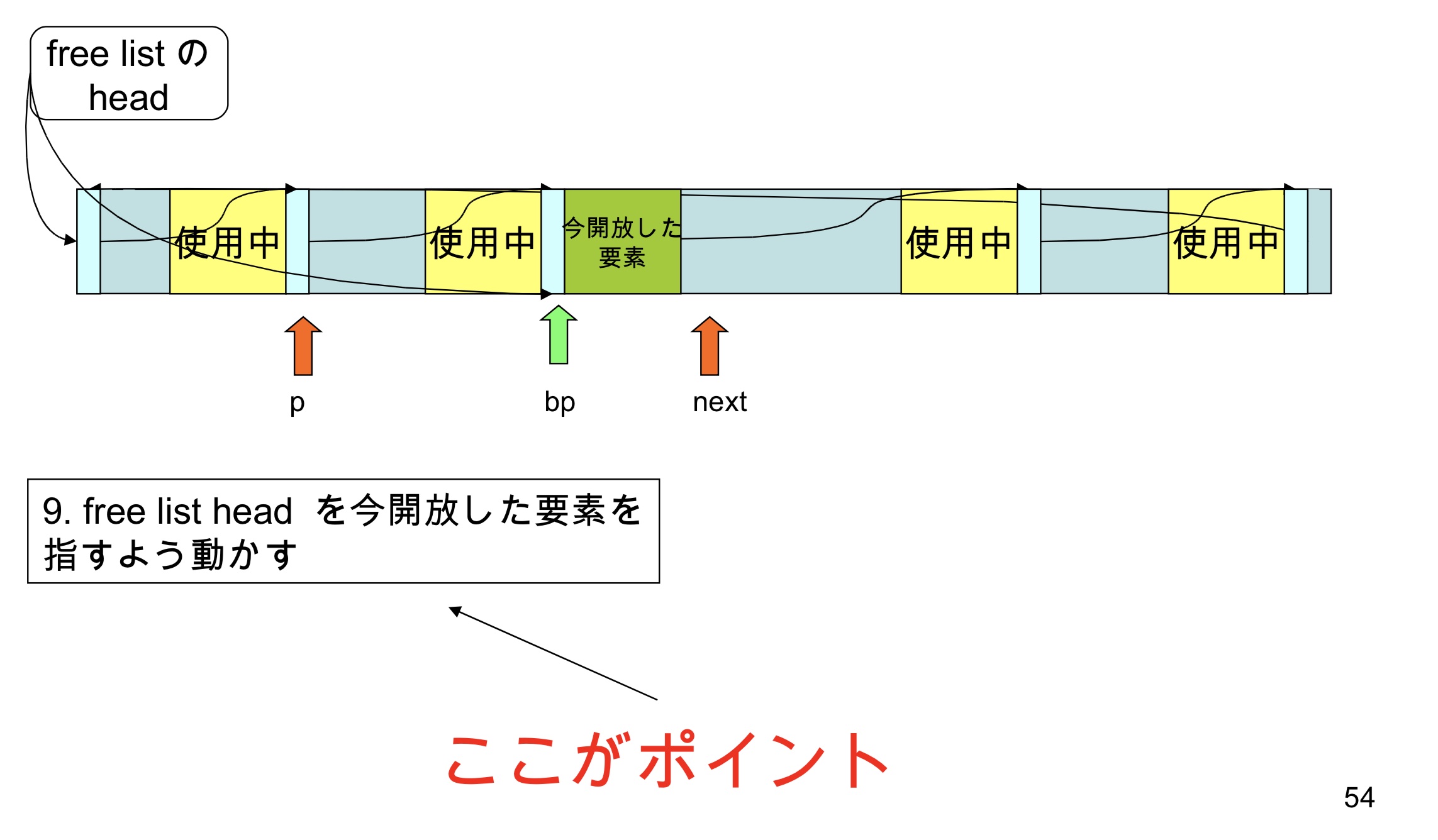
- 现在free list head指向释放掉的节点
缓存和本地引用
- 对heap内存访问概率最高的是在malloc之后立即free
- 刚刚free的内存在缓存上的概率很高
- 为了优先确保内存,malloc之后直接访问,不会出现缓存miss
缓存命中率很重要
缓冲区的延迟合并
- 当调用free时,立即 与相邻空间合并,并且暂时不会进行连接到free list的处理
- 最初实现这种方式的是SVR4(相当早的UNIX内核)
- malloc-free-malloc-free这类常见的访问模式导致内存块的分离-合并-分离-合并之类的不必要处理,延迟合并能够避免这种情况。
- 并且,由于按照时间顺序对free进行连接,因此将列表头部的block返回到应用程序可以提高缓存命中率。
- glibc malloc的最低确保单位是32,bin[0]和bin[1]不能使用
- bin[1]用来存放这个延迟的block所要连接的list的header
- 源码中叫做unsorted_chunk,不进行排序,而是按照时间顺序
- 通过遍历列表,找到与要求size一致的
- 与要求size不一致的,在这个时间,与相邻空间合并后进行实际的free处理
从宏观角度
- malloc的调用模式大致上是以下流程
- 应用启动时会调用malloc,很少调用free
- 之后,进入malloc和free大体上交错被调用的正常状态
- 像GUI画面切换之类的,会触发,free被单独调用,之后malloc被调用,数据结构体也会有大的变化
- 之后再次进入正常状态
malloc的正常状态和突发状态
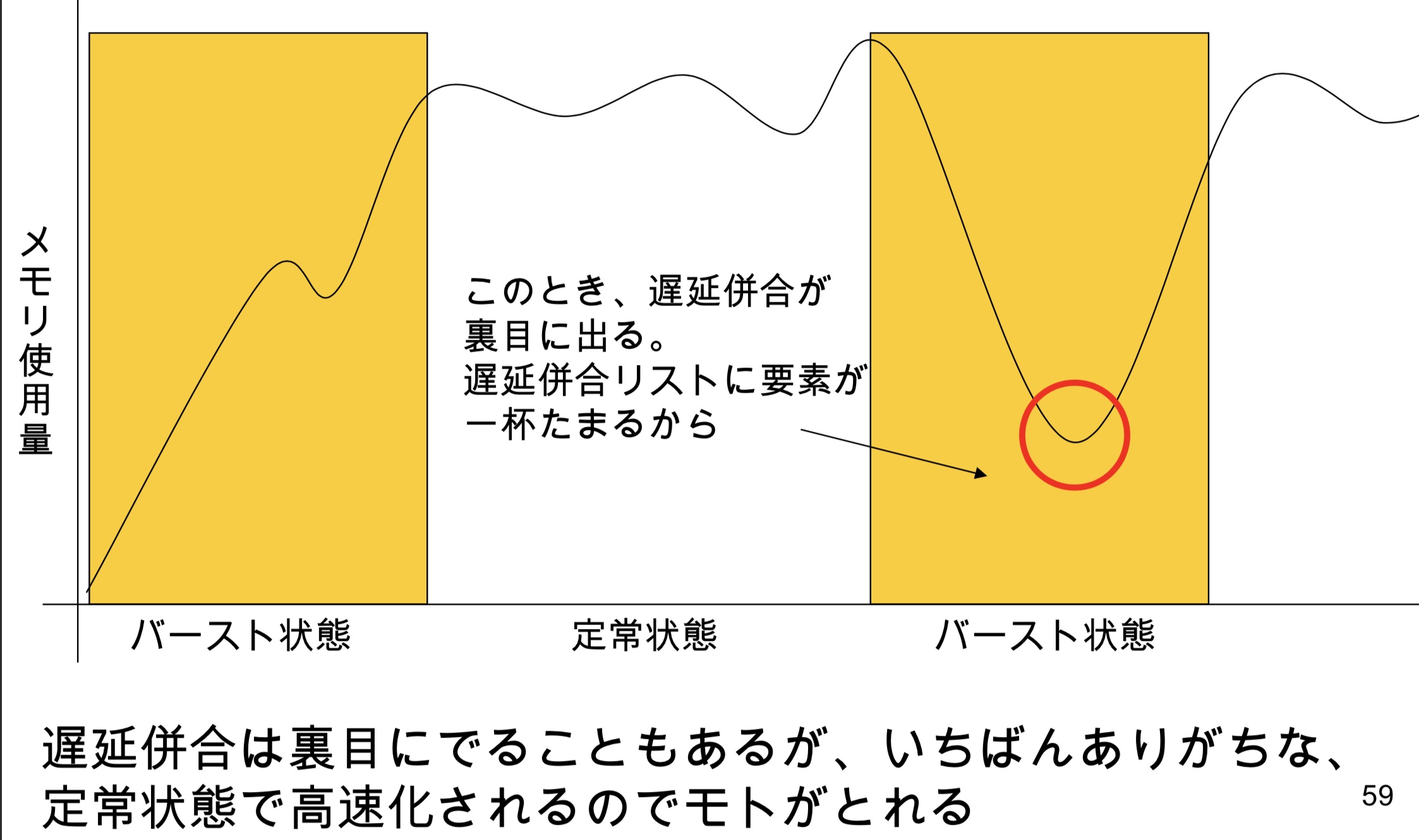
延迟合并有时会事与愿违,但可以接受,因为它在正常状态下是高速化的
