Arena 1M对齐方法图解
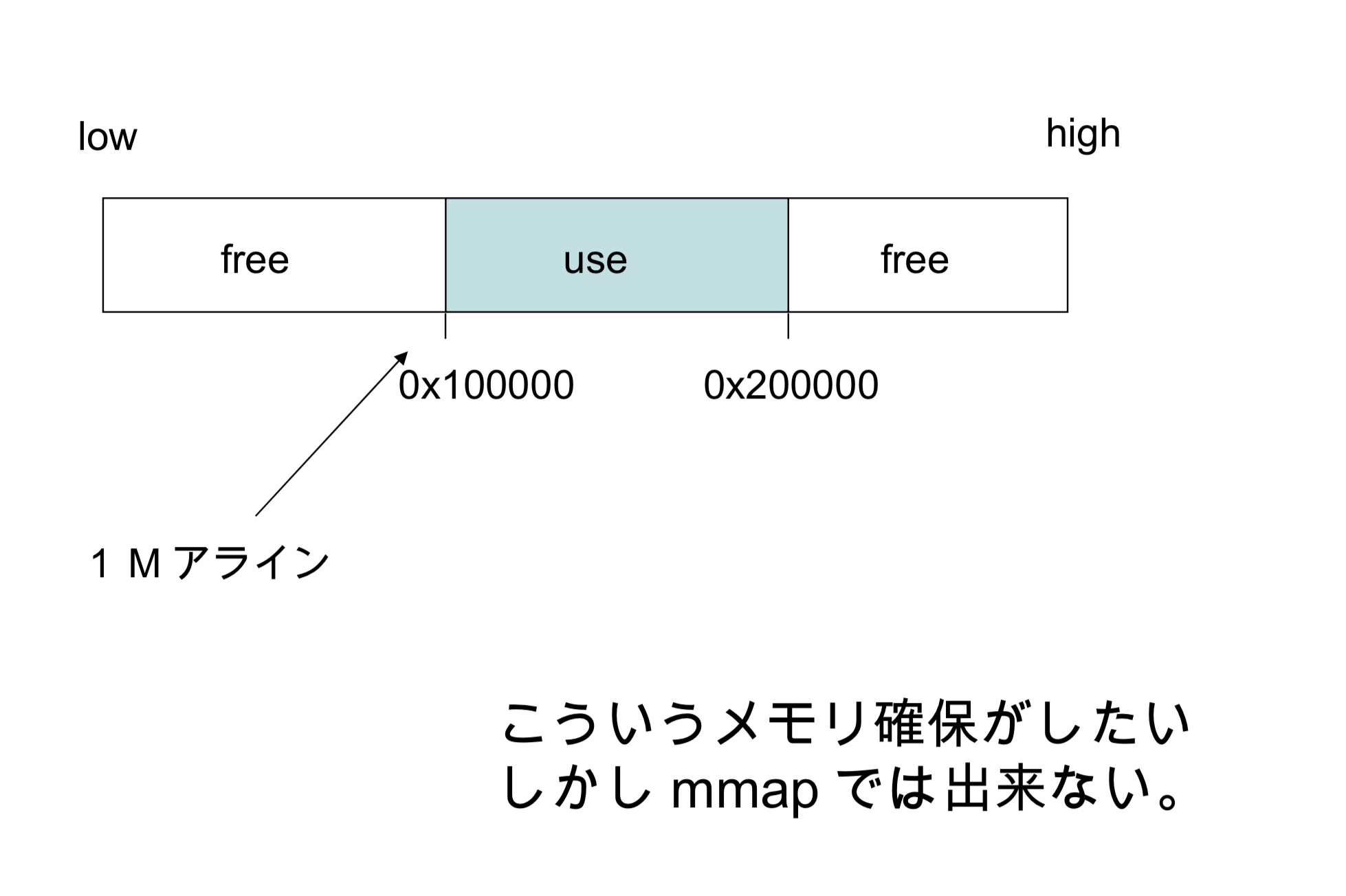
想要的是这样的内存
但通过mmap做不到这一点
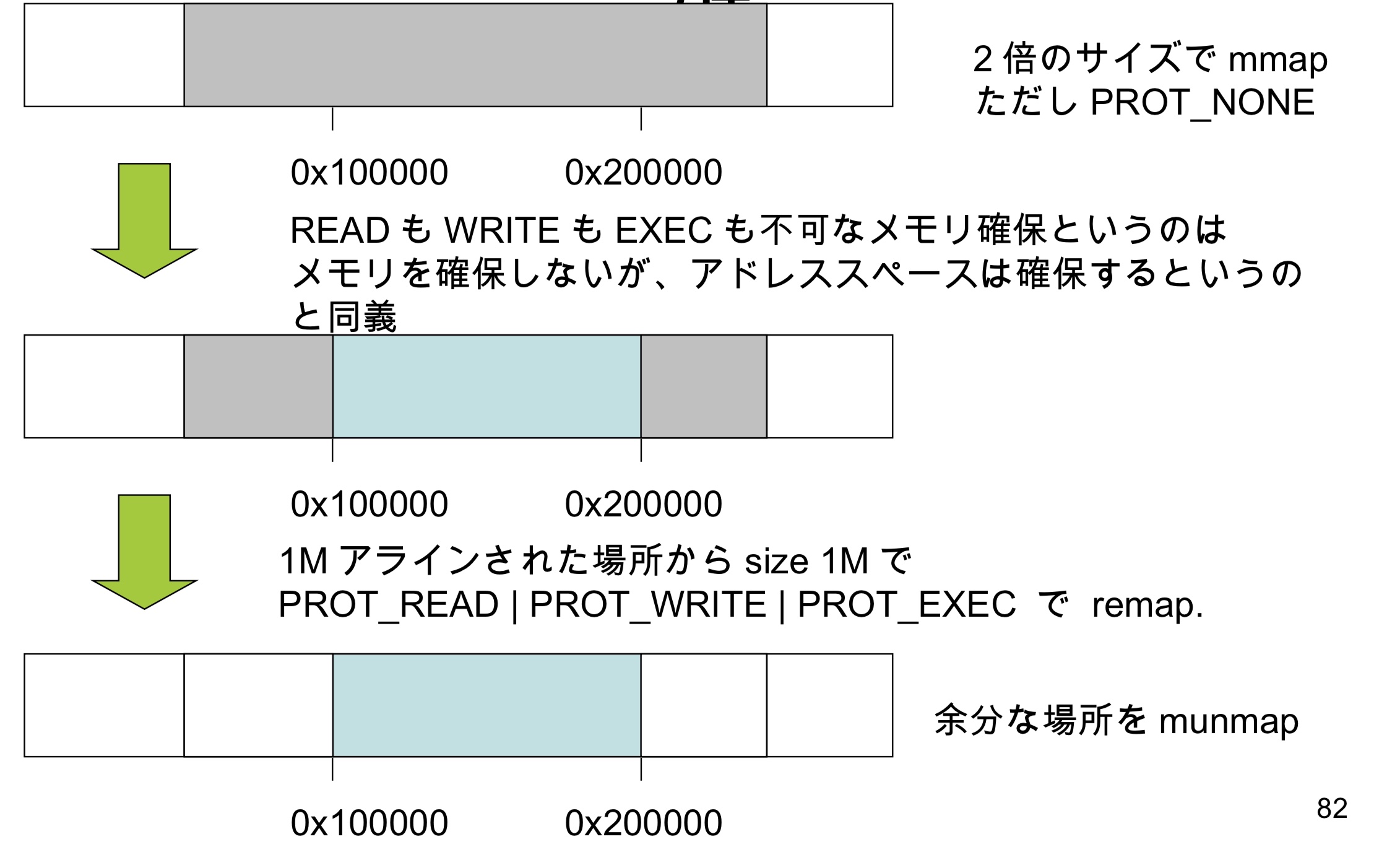
2倍size的mmap
但是PROT_NONE
RWX权限都没有,这已经不能算内存分配了,可以叫做地址空间
1M对齐的场所中,通过remap对size 1M进行RWX权限分配
剩余的空间进行munmap
总结
- 小型malloc如果经常出现的话,复杂度是O(n),太糟了
- 防止碎片化,Huge Block将heap分开是有效的
- 要提高缓存命中率,引用局部性非常重要
- 每个线程的数据结构是每个CPU的数据结构的良好近似值
glibc malloc的缺点
- 由于Huge Block是绝对页对齐的,缓存很容易出现竞争(在HPC领域中通常关闭此机制)
- 如果是用另一种方式,将不会锁定Arena自身(这就是产生问题的heavy allocation,应用作heap自身管理,很难看到效果)
- 最新的dlmalloc对large bin的管理已经从列表变成了二叉树来提高速度(尽管利用率太低,效果很微妙)
最终
- glibc malloc是今天的主要内容,针对int_malloc各个方面将近90页的PPT阅读不容易
- 源代码中的注释我觉得是在骗我,阅读用了差不多一小时
- 函数划分用了有两小时
- 构造体类型与内存上的数据结构对应用三小时
- 这样看起来Linux 内核还是很容易读的嘛
