PlaidCTF 2015 - pwnable620(420+200) - tp
Use After Free + sandbox逃逸
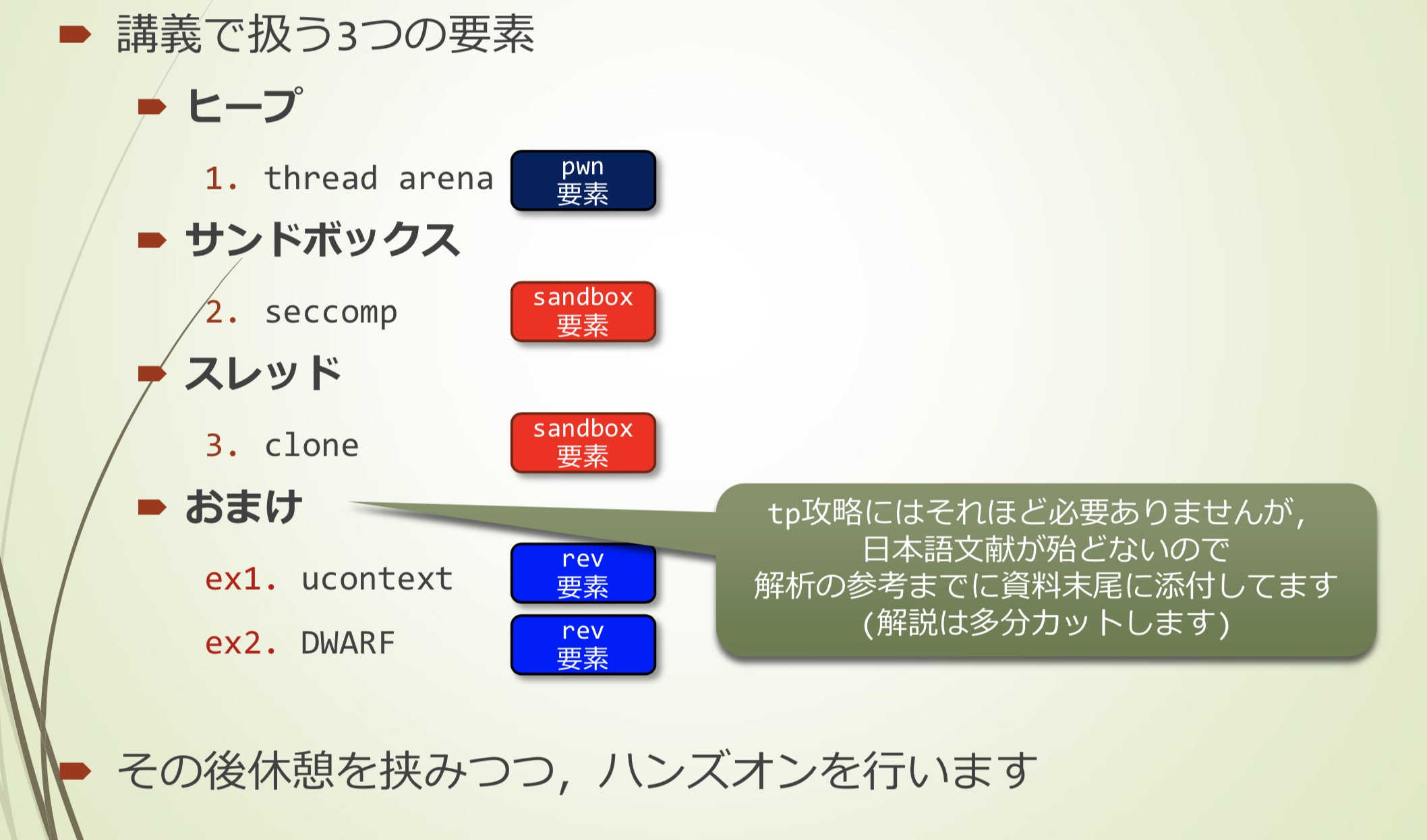
主要三个点
- heap
- thread arena
- sandbox
- seccomp
- thread
- clone
扩展部分并不是解题必须的,但因为相关资料较少,作为补充内容
heap
The Malloc Maleficarum
- 有点老(x86, glibc-2.3.5),使用malloc/free进行exploit的5种技术
- 除了House of Prime之外其他四种仍然有效
- 这里的环境是glibc-2.20
- House of Lore
- House of Mind
- House of Force
- House of Spirit
The Malloc Maleficarum简单解说
House of Lore
consolidate之后对smallbins/largebins的unlink attack。将free状态的chunk的bk修改为任意地址,之后第一次malloc到free_list的开头,第二次malloc则是我们控制的地址。尽管在unlink时已有检查机制,但是如果是相互正确引用的chunk,free状态chunk的bk指向它的话是有效的。另外,在fast bins的link list获取不检查fd/bk的size非常简单。这就是fastbins attack,本质上是House of Lore的一种
https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/house_of_lore-zh/
House of Lore 攻击与 Glibc 堆管理中的的 Small Bin 的机制紧密相关。
House of Lore 可以实现分配任意指定位置的 chunk,从而修改任意地址的内存。
House of Lore 利用的前提是需要控制 Small Bin Chunk 的 bk 指针,并且控制指定位置 chunk 的 fd 指针。
House of Mind
- 构造一个设置了NON_MAIN_ARENA比特位的chunk进行free的攻击。查找chunk所属arena的计算是(p&0xfff00000)->ar_ptr,在p&0xfff00000构造伪造的heap_info和arena,将伪造的heap_info->ar_ptr指向伪造的arena,在伪造的arena->bin[0]中设置GOT-8之类的。NON_MAIN_ARENA的chunk在free时,free的chunk连接到那个GOT,造成GOt被修改。目前已被修改,unlink时加入了(对unsorted_chunks是fwd->bk != bck)验证,但是对fastbins仍然有效
House of Force
- 将top chunk(heap最后的chunk的下一个)的size修改为0xffffffff的一种攻击。之后,malloc(攻击者指定的大小),可以获取到非常大的内存。对内存空间遍历一次,top chunk可以到达heap之前的bss,下一次malloc就可能获取到GOT。这种方式现在仍然有效
- https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/house_of_force-zh/
House of Spirit
- 如果存在类似chunk结构的内存,则可以通过free它在free_list追加它的地址。stack或者bss上进行free,下次malloc将返回GOT或者stack地址。这种攻击现在仍然有效。
House of Prime
- 确认一个chunk是否属于fastbins,是通过arena中的av->max_fast作为阈值来确定的。因此,如果将av->max_fast伪造为较大的值,则可以将任意内容注册为fastbins。对8比特size的chunk(原本最小size的chunk是16比特,伪造成8比特)进行free时,会注册到av->fastbinsY[-1]。这意味着在av->fastbinsY[]之前的变量av->max_fast被重写为较大的值。接下来,当free另一个chunk时,即便是size非常大的chunk,只要在av->m ax_fast以下,就会被作为fastbins处理,那么它将在超出av->fastbinsY[]限制的数组中注册。因此,可以覆盖av->fastbinsY[]之后的av->arena_key。这是多线程程序中有意义的arena指针。下一次进行malloc时,av->arena_key会被覆盖,引用它就能够获得arena。这相当于处理一个刚被free成arena的大的chunk。如果在这个chunk的fastbinsY[]或者bins[],unsorted_chunks等设置GOt,那么在free后,malloc则会返回GOt。现在此方法已失效,因为已经不存在av->max_fast,已经更改为一个global_max_fast的全局变量。
how2heap
Shellphish战队的资料
https://github.com/shellphish/how2heap
- fastbin dup
- fastbin dup into stack
- unsafe unlink
- poison null byte
- overlapping chunks
- …
1. thread arena
malloc(-1)
- malloc或者new,参数作为unsigned long处理,所以附属会变得非常大
- 即使是单线程,也会发生切换到thread arena(mmap-ed arena)
- malloc和new基本是相同的,下面用malloc解释
分析malloc(-1)
malloc()内部是怎么样的
- 这里用glibc(2.19)的源码
- http://osxr.org:8080/glibc/source/malloc/malloc.c
从__libc_malloc()入手比较好

- 是一个strong_alias
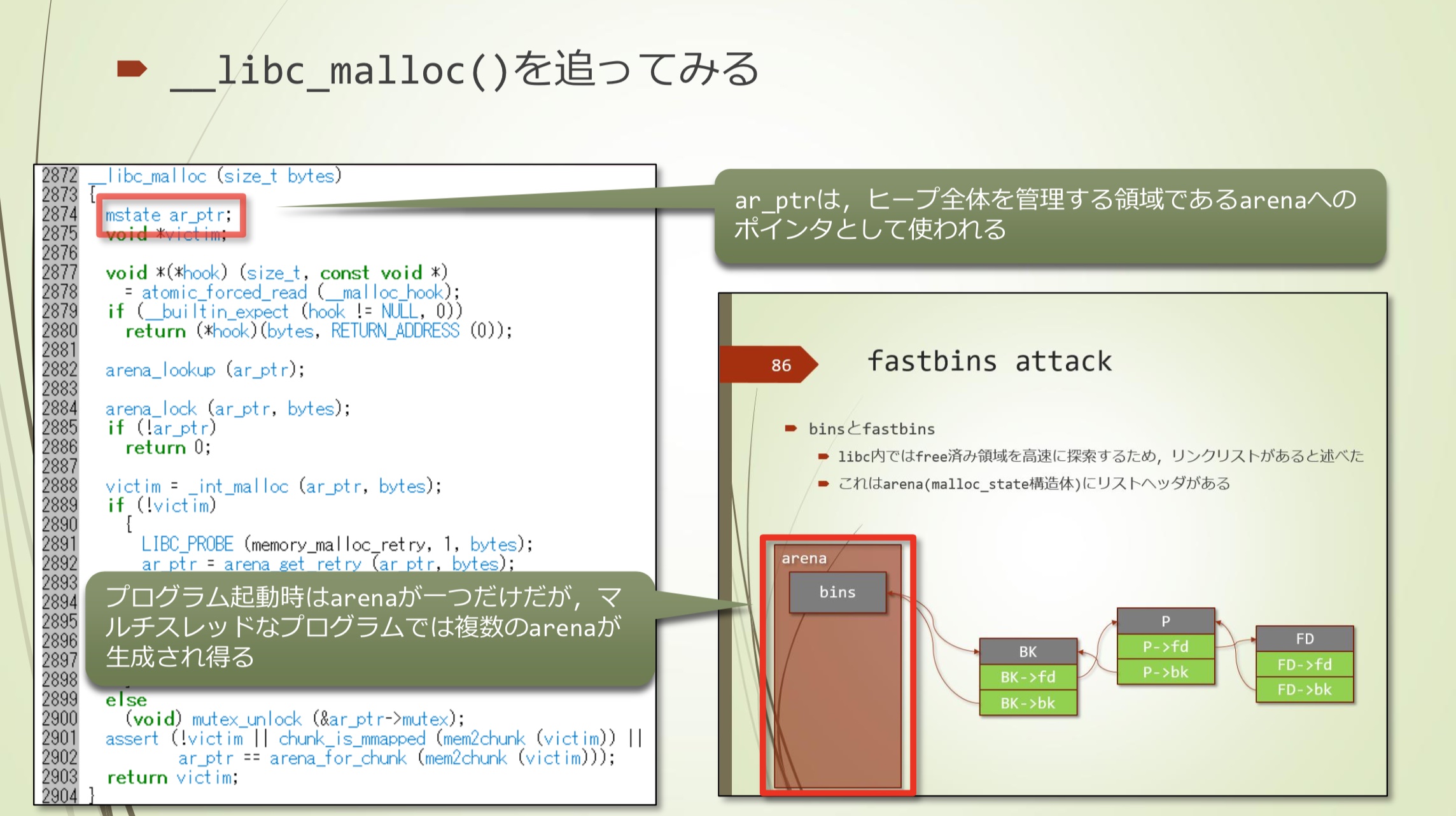
- ar_ptr是指向管理整个heap的arena的指针
- 虽然程序启动时只有一个arena,但多线程可以生成多个arena
malloc option的setup

- __malloc_hook有设置的话则会调用它。通常,第一次调用malloc()时,会包含malloc_hook_ini() 的地址。
- 这在内部被称为ptmalloc_init(),如果malloc的操作变更由环境变量指定,则相应的由__libc_mallopt()反映
- 之后,main_arena的地址作为[当前arena]保存在TLS区域中,并且再次调用__libc_malloc(bytes)
- TLS区域:Thread Local Storage。
- C语言的static变量或者全局变量保存在data或者bss中。通常,多线程程序的内存空间在线程之间是通用的,因此,相同的值存储在所有线程中。但是,某些情况下想要在不同线程之间使用不同的静态或者全局变量,则可以用过TLS机制使得每个线程都是独立的全局变量。
- 此时,用作保存的区域是TLS区域,并且为每个线程分配了不同的存储区域(因为线程共享存储空间,因此TLS区域等于存储空间中的线程数)。访问时,将根据每个线程保存的key来确定使用哪个TLS区域。
获得当前crena

- 通过arena_lookup()获取TLS区域中当前arena的地址
- 如果是单线程,TLS只有一个,获得的就是之前设置的main_arena
- 如果是pthread_create()创建的多线程,每个线程都有一个单独的TLS,因为在创建线程后立即清零,所以获得的返回值是0
锁定当前arena
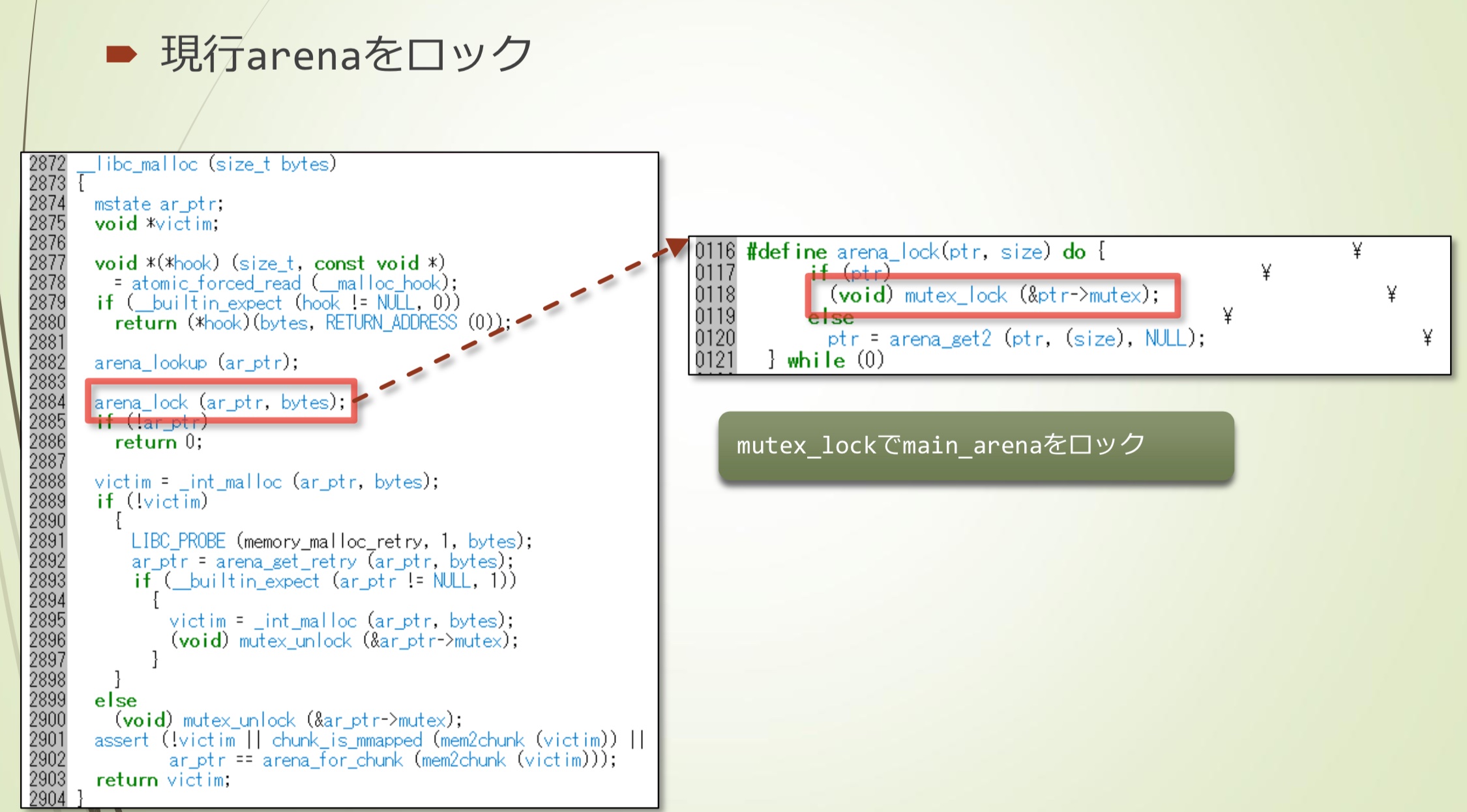
- 通过mutex_lock对main_aren进行锁定
通过 _int_malloc(),从main_aren申请内存

- _int_malloc(ar_ptr, -1)
- 64位环境下, -1 == 0xffffffffffffffff,内存分配失败
- 因为堆中内存分配失败,此时victim = 0
进行重试,在内部生成新的arena
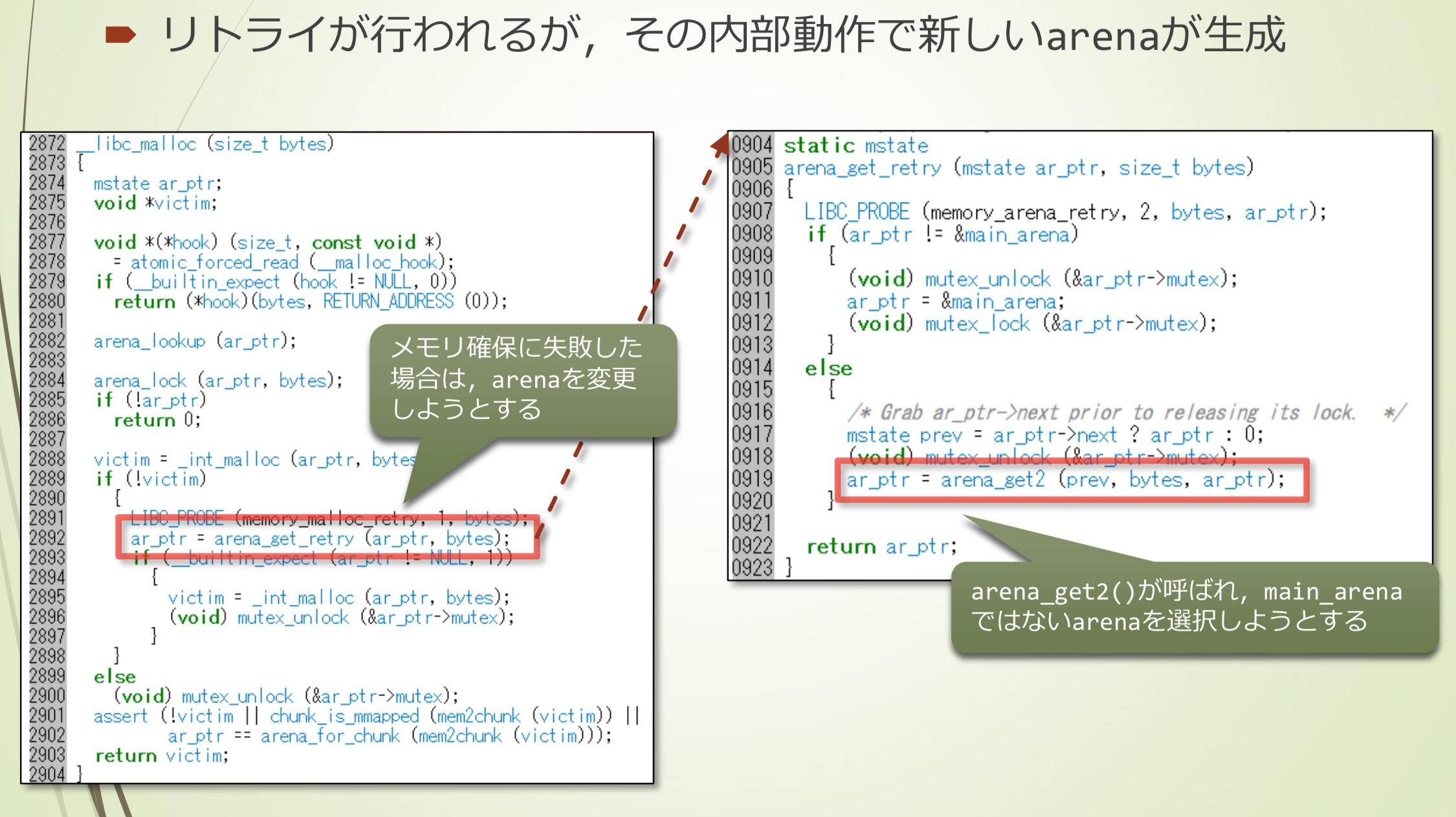
- 因为内存分配失败,尝试变更arena
- 调用arena_get2(),尝试选择不是main_arena的arena
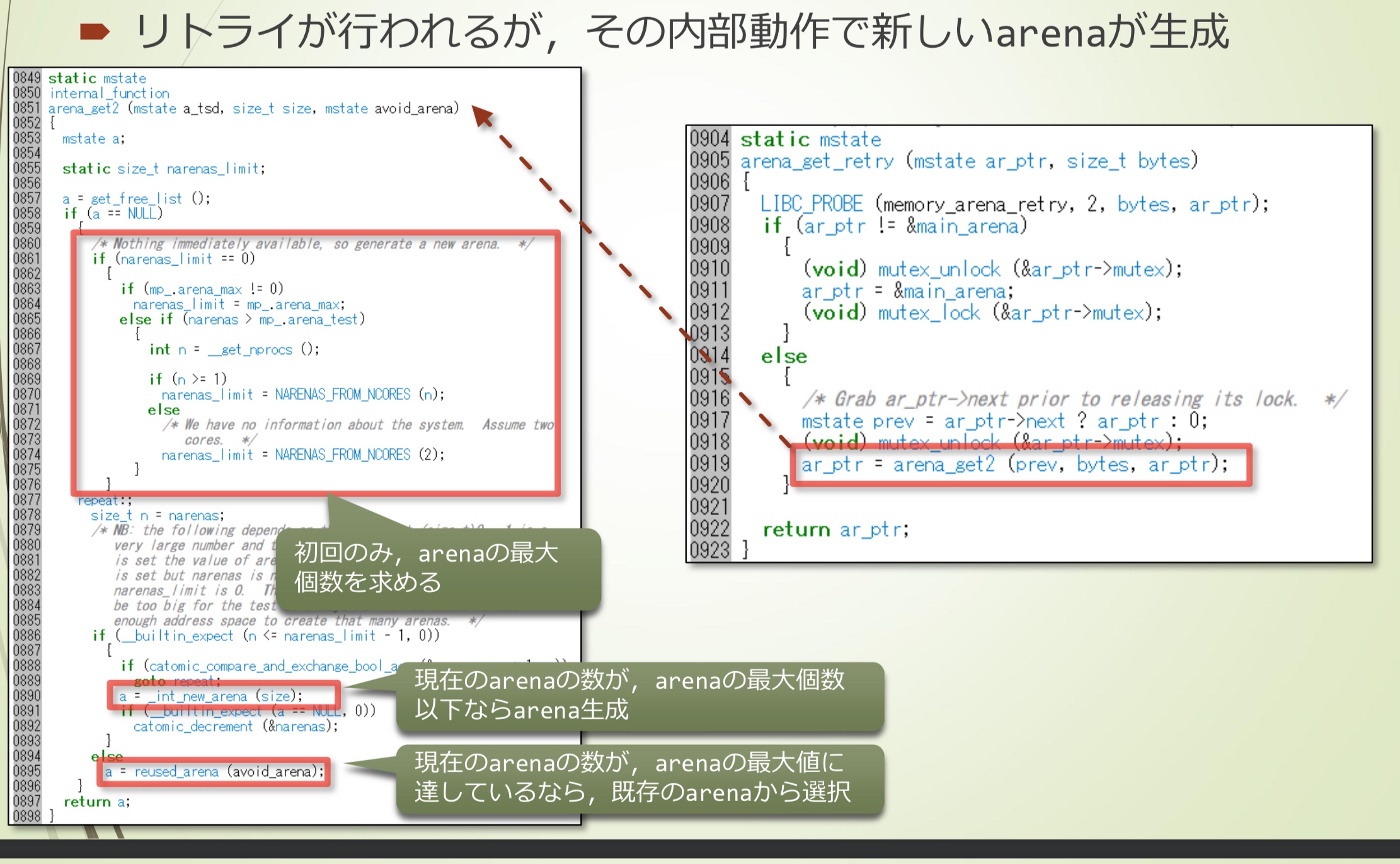
- 首先,获取arena的最大个数
- 如果当前arena的数量小于最大数量,则会生成新的arena
- 如果当前数量已经到达最大数量,则从现有arena中选择

- 生成新的arena
- 更新TLS区域中当前arena的指针,以优先使用新生成的arena
- 返回新的arena
- 这就是thread arena(并不是正式叫法)
从arena_get_retry()返回后,使用thread arena尝试重新分配内存,失败

- 使用thread arena,再次调用_int_malloc(),结果也是失败
解锁,malloc()返回NULL

- unlock
- 返回NULL
动态调试
一个简单的例子:
1 |
|
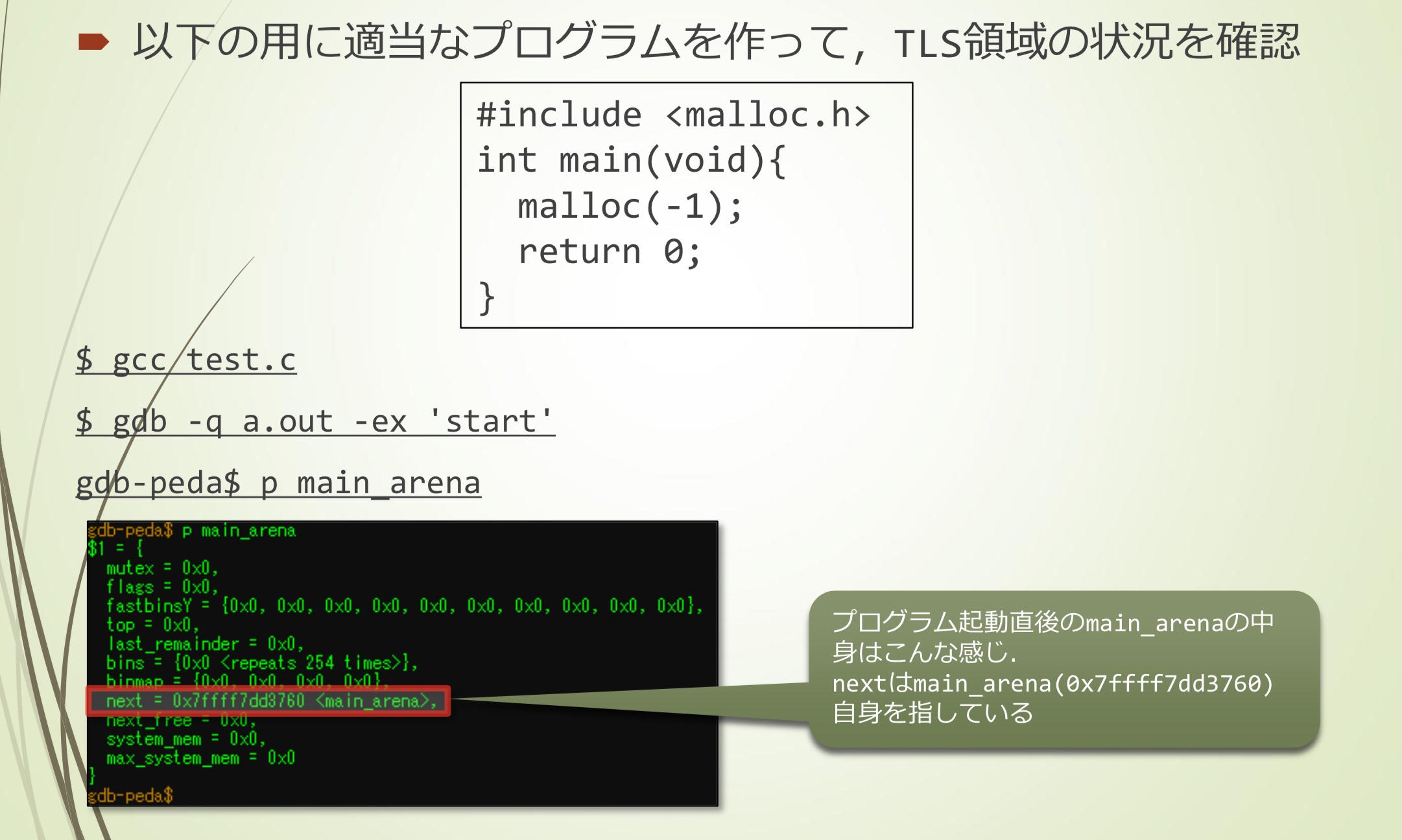
程序运行后main_arena内部大概是这样,next指向main_arena自身
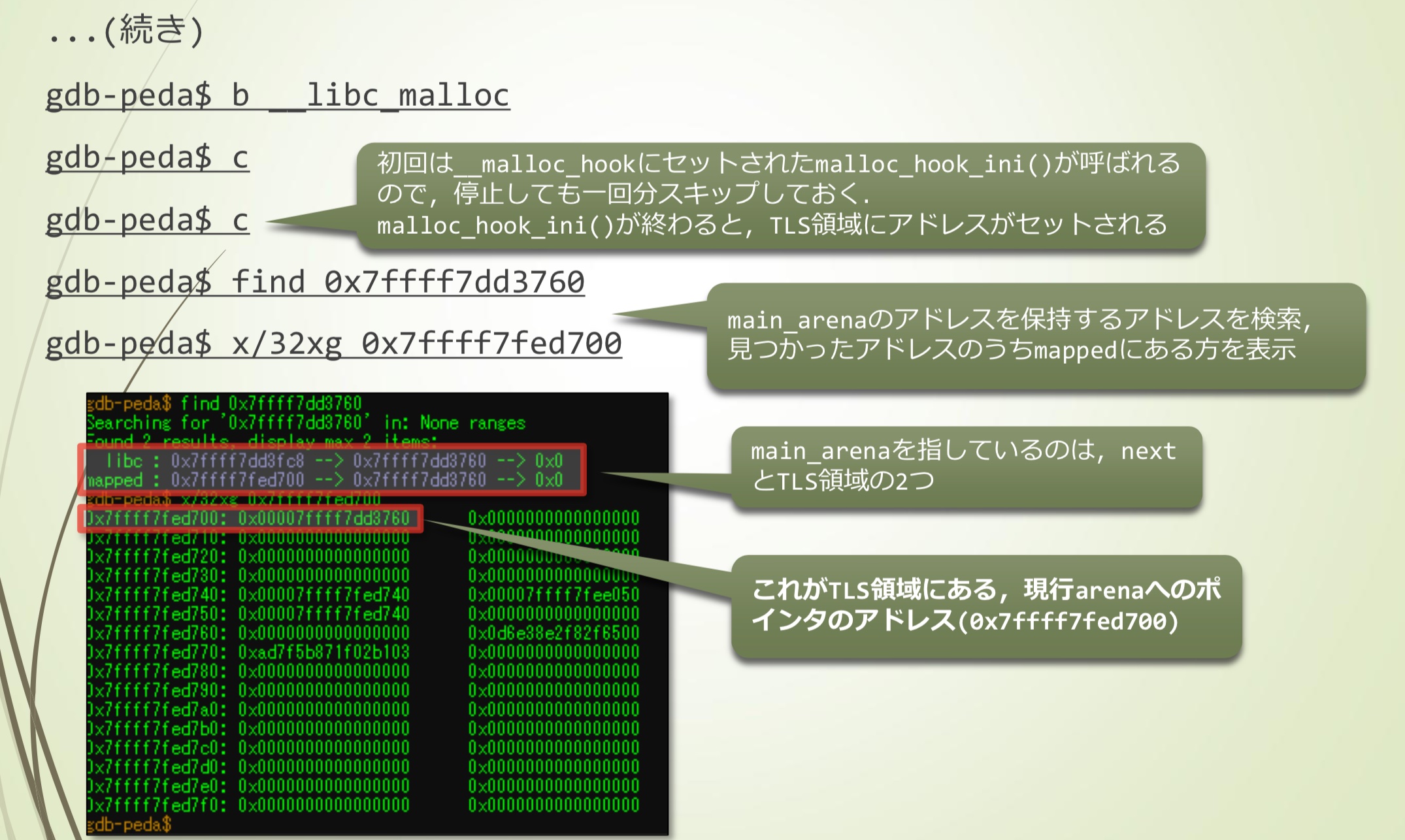
- 第一次调用设置__malloc_hook的malloc_hook_ini(),即便停止也会跳过一次。malloc_hook_ini()结束后,TLS区域中设置了地址。
- 搜索包含main_arena地址的地址,在mapped中也发现有
- 指向main_arena的有两个,next和TLS区域
- 这个是TLS区域中指向当前arena的指针的地址(0x7ffff7fed700)

- 调用arena_get2()后,生成了新的arena
- 调用arena_get2()后,main_arena内部是这样,next的地址改变了
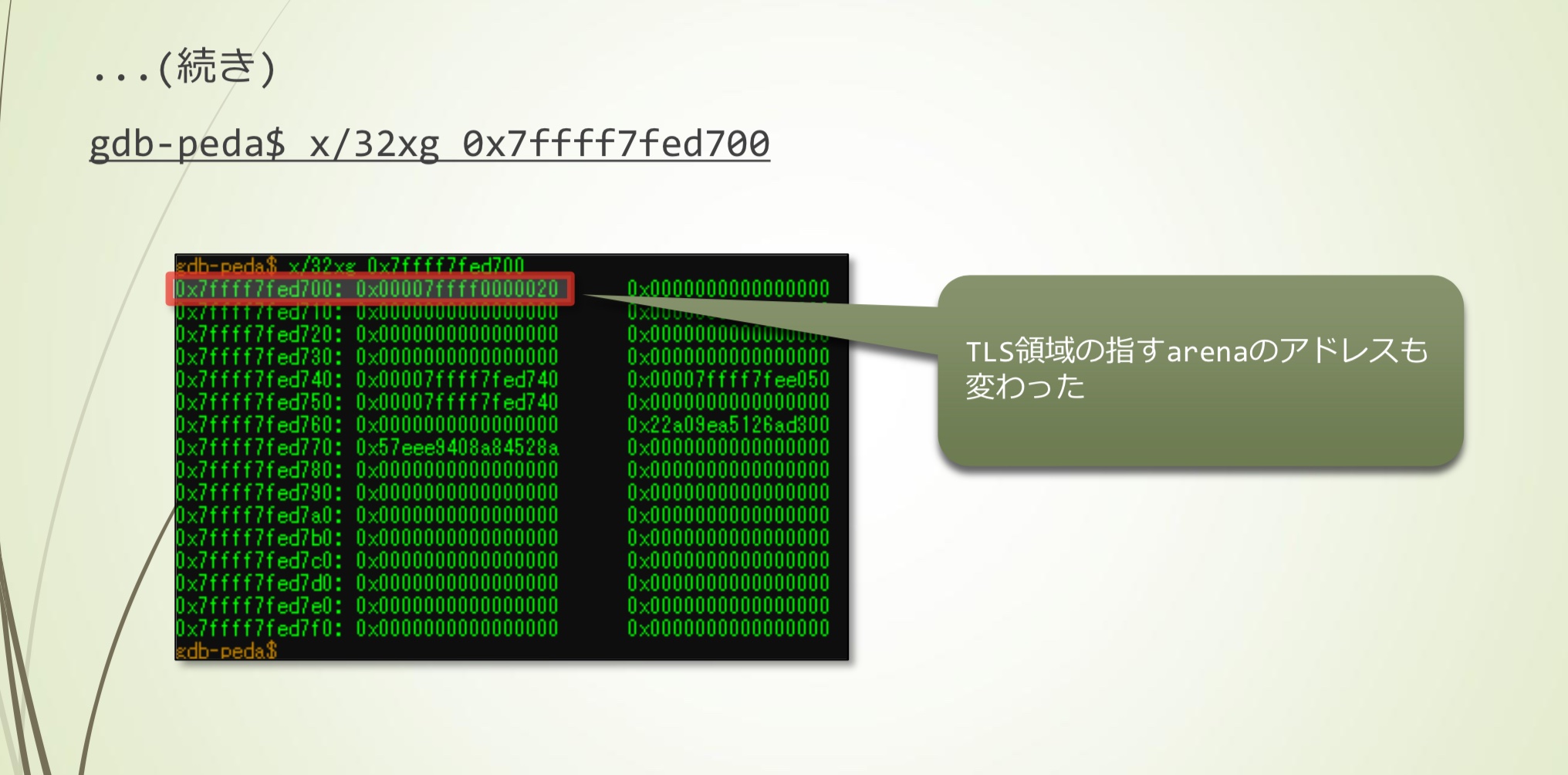
- TLS区域中指向arena的地址也改变了
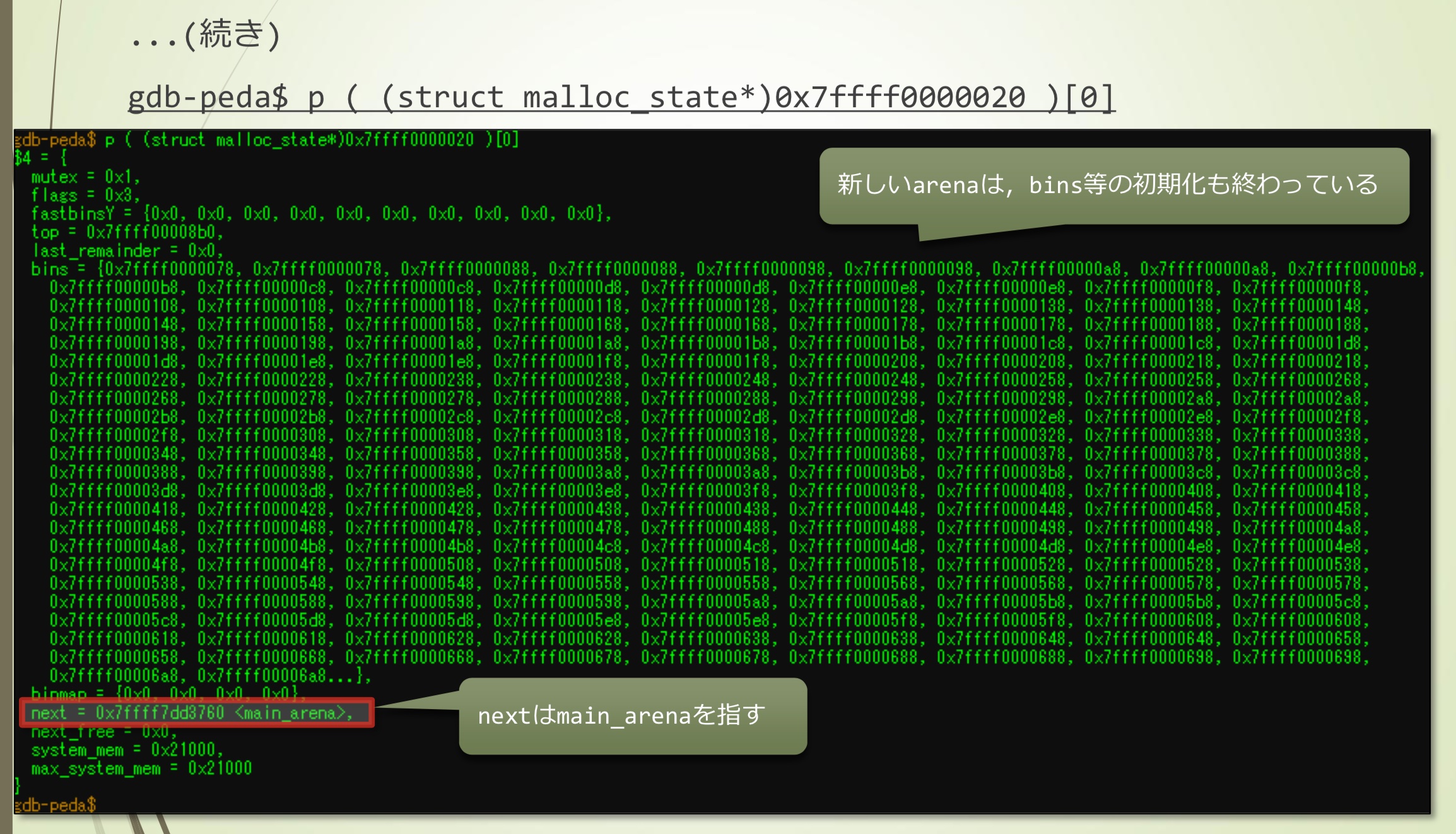
- 新的arena,bins的初始化也完成了
- next指向main_arena
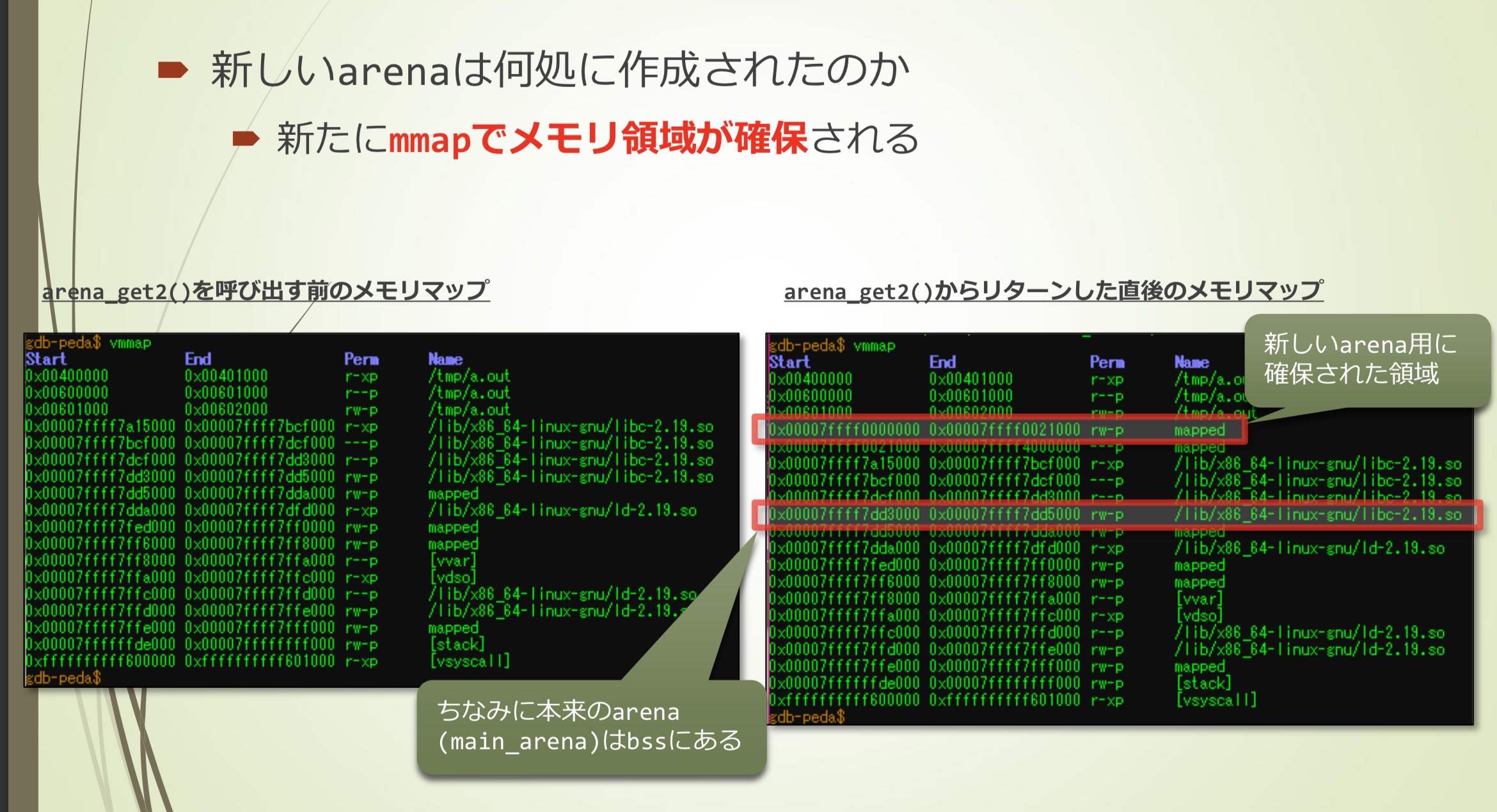
- 对比arena_get2()调用前后的内存映射状态,可以看出原本的arena(main_arena)是在bss区域,新生成的arena是通过mmap获取的内存
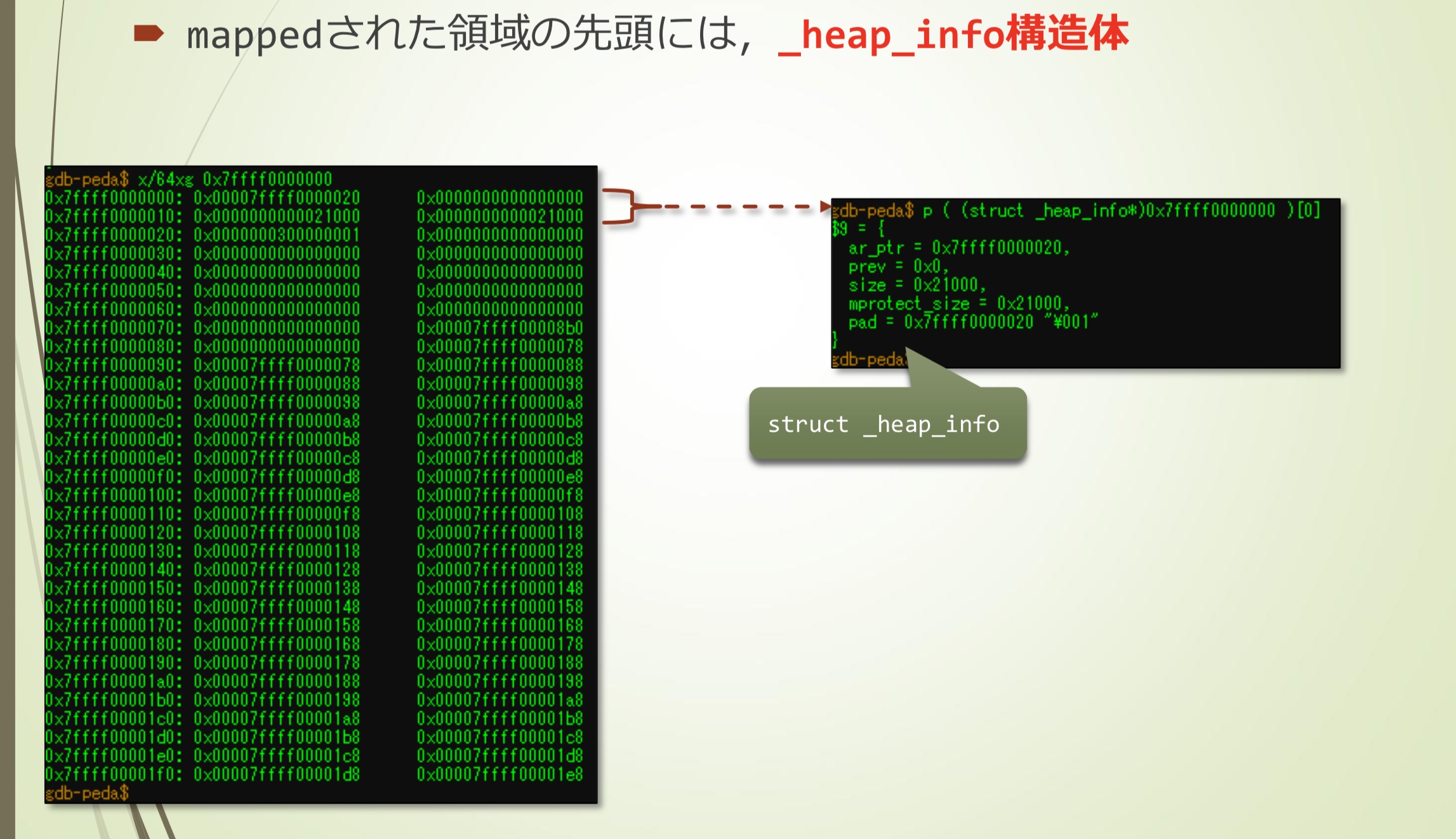
- mapped内存区域前面,是_heap_info结构体
- 后面配置了thread arena
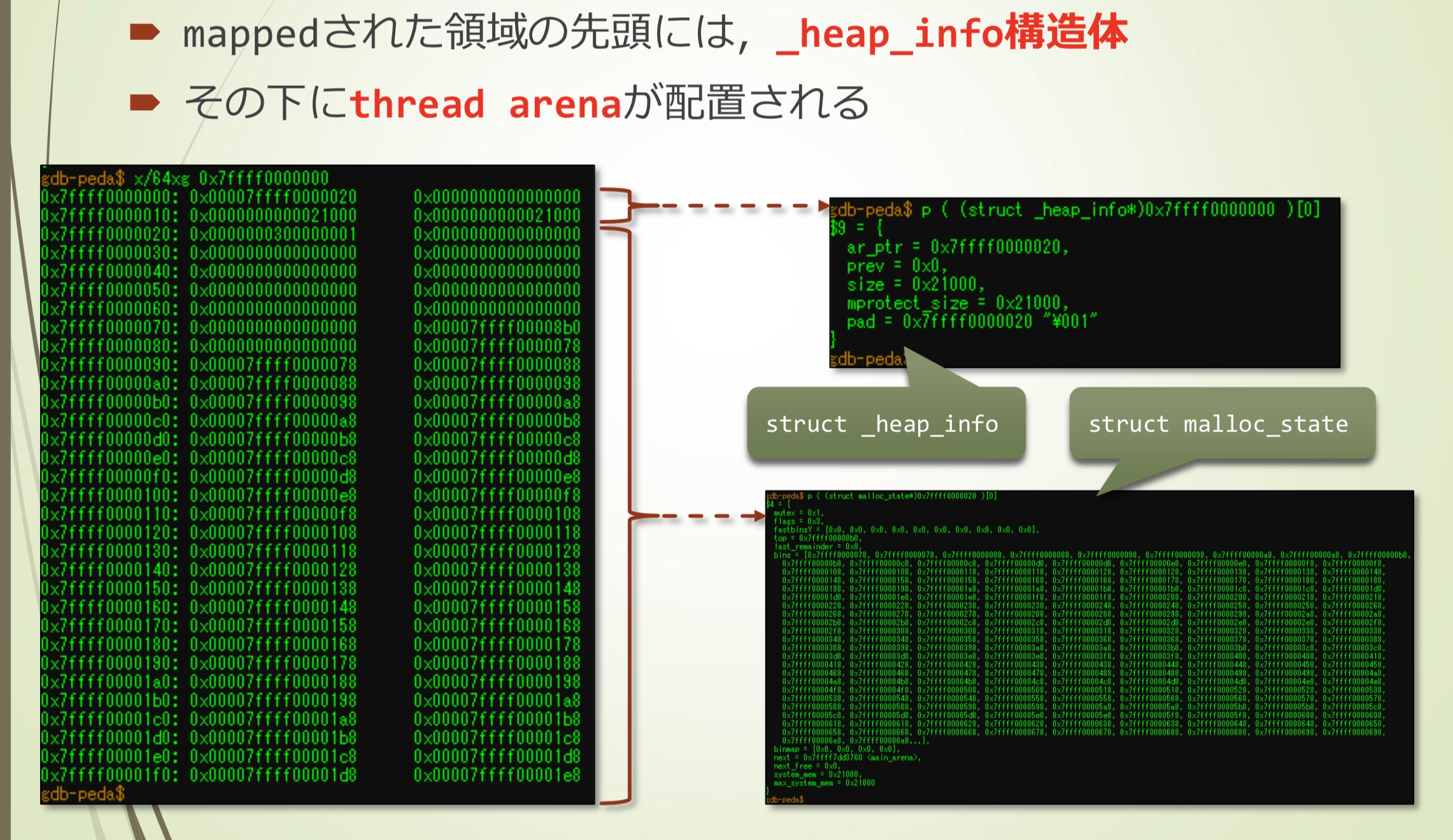
- 图示大概这样

- 后面是heap的chunk使用的区域
malloc(-1) X 2
那么,thread arena生成后,再次调用malloc(-1)呢?
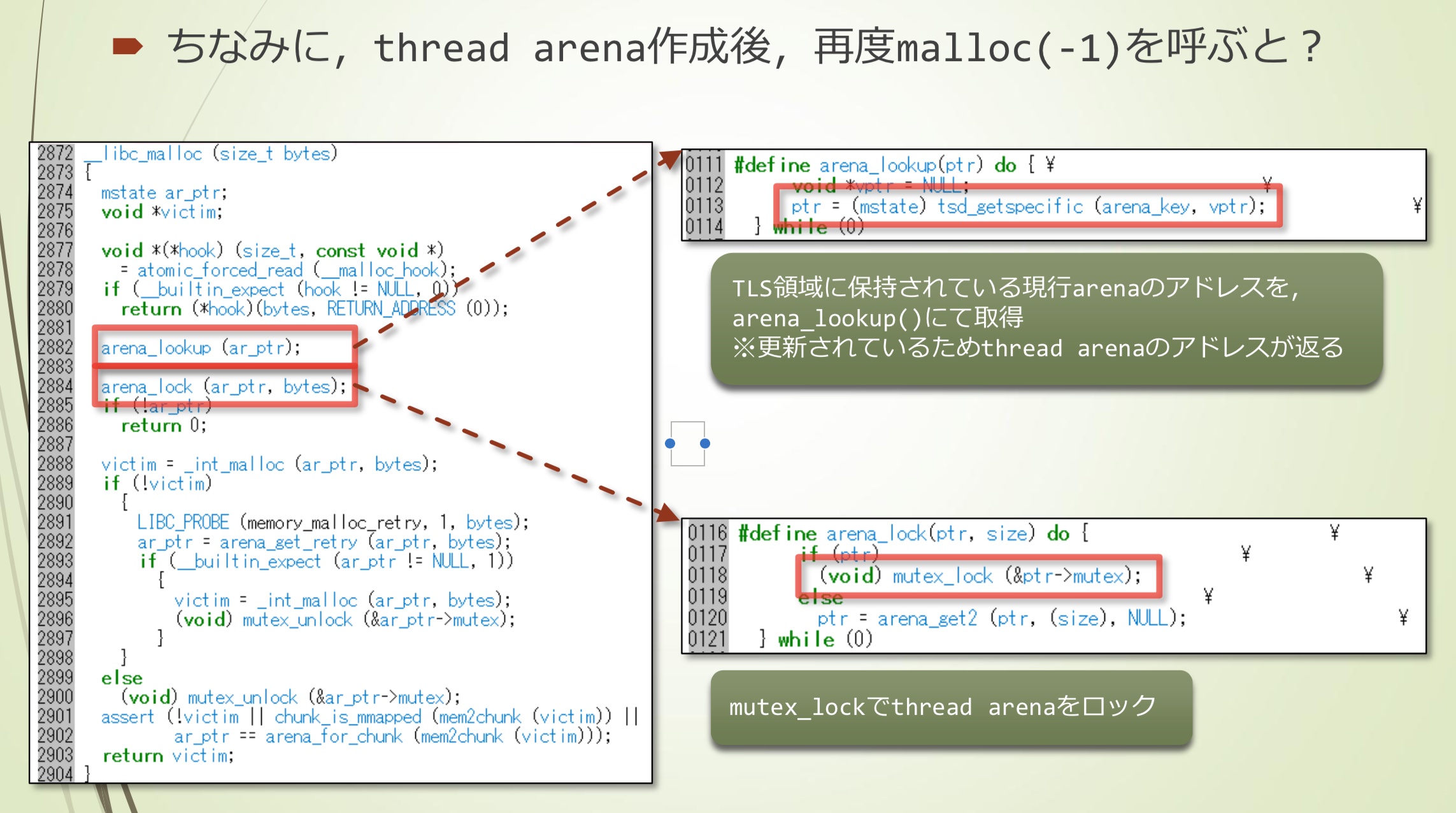
- 通过arena_lookup(),从TLS区域获得arena的地址(更新后的thread arena地址)
- 通过mutex_lock锁定thread arena

- _int_malloc()失败
- 调用arena_get_retry()
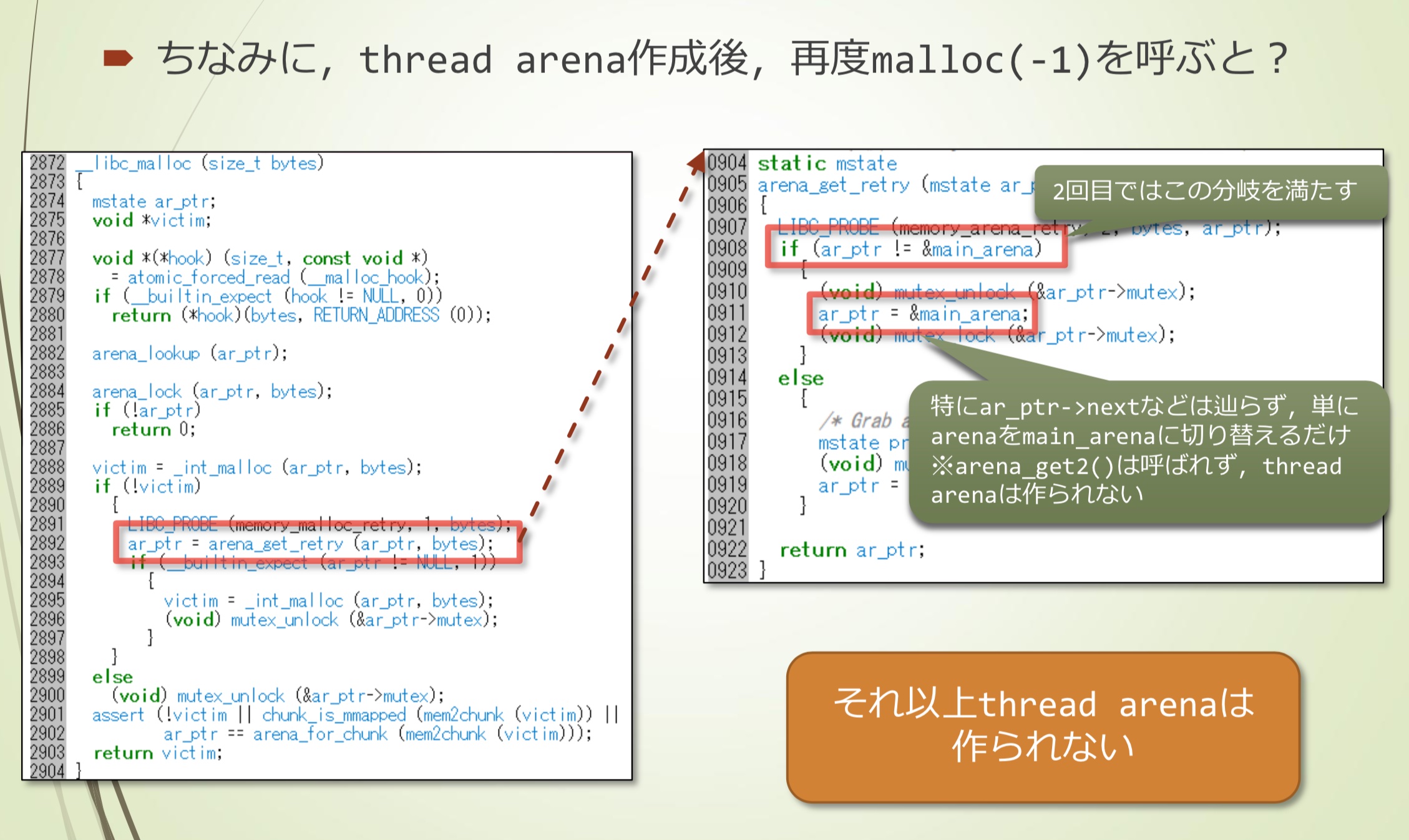
- 第二次满足这个分支判断
- 不需要关注ar_ptr->next,只需要将arena切换到main_arena(不调用arena_get2(),不会生成thread arena)
malloc(-1)总结
- TLS的指针
- 当前arena由TLS区域的指针变量进行管理
- arena
- 管理heap区域的arena,原本只有main_arena一个
- 通过malloc(-1)的失败,生成thread arena
- TLS区域的指针变量,也变成指向thread arena
- thread arena的数量
- 每个线程最多一个thread arena(加上main_arena共两个)
- 多数情况下,thread arena与线程一一对应
- 但是也存在线程间共用thread arena的情况
- 达到arena的最大值,会出现这种情况
补充
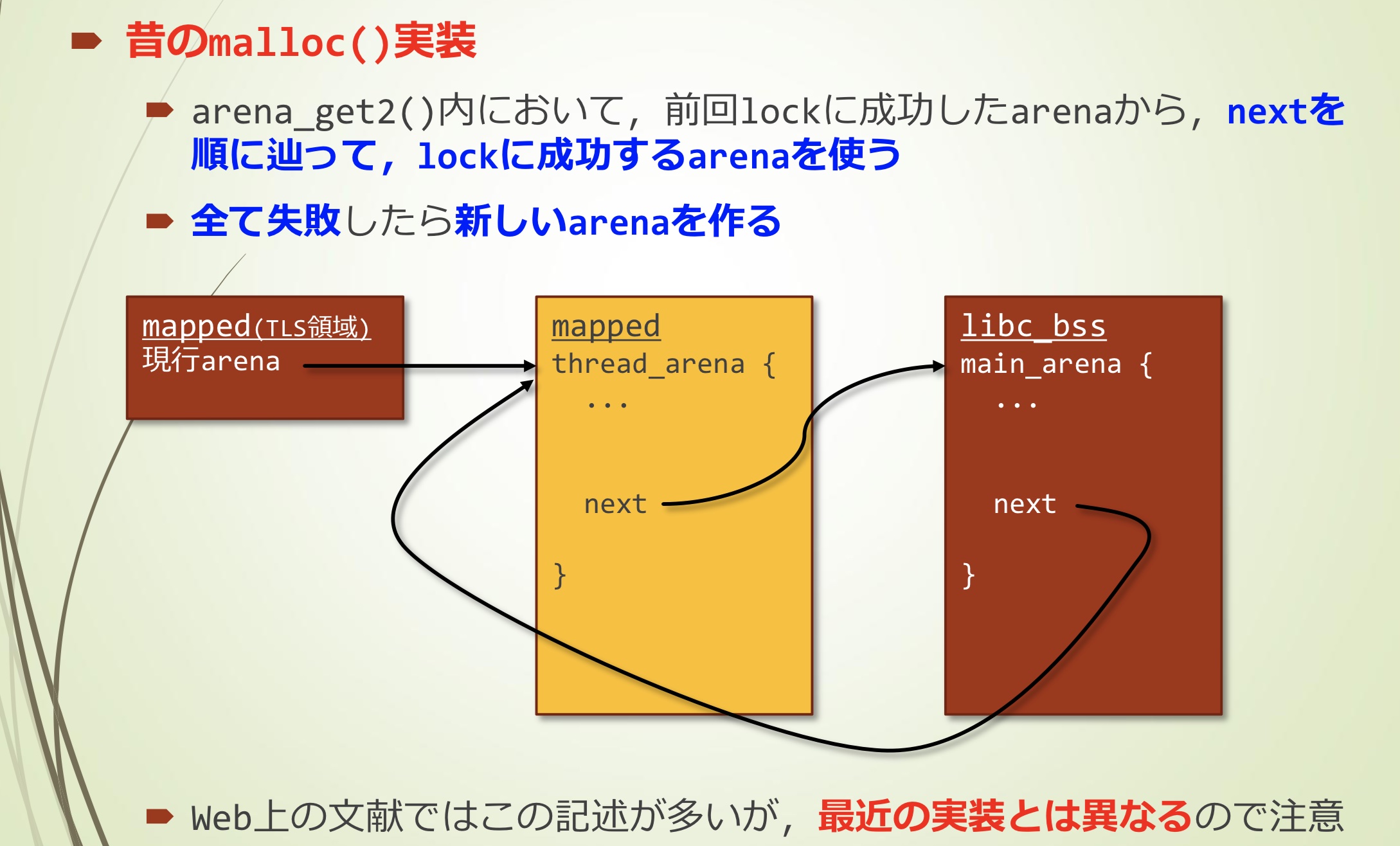
以前的malloc()实现
- 在arena_get2()中,从上次lock成功的arena,通过跟随next使用lock成功的arena
- 全部失败才会创建新的arena
现代malloc()实现 — 通过pthreads创建多线程的情况
- 生成线程时,TLS区域也是新生成的
- 在新的TLS中,当前arena的指针被清空
- 因此,线程中第一次调用malloc时必定会调用arena_get2(),基本上会为每个线程创建一个thread arena
- 但是arena的数量存在最大值,如果超出,arena_get2()会使用已存在的arena作为当前arena(reused_arena(),通过arena的next来选择一个arena使用)
- 这种情况下,会存在同一个arena被多个线程使用

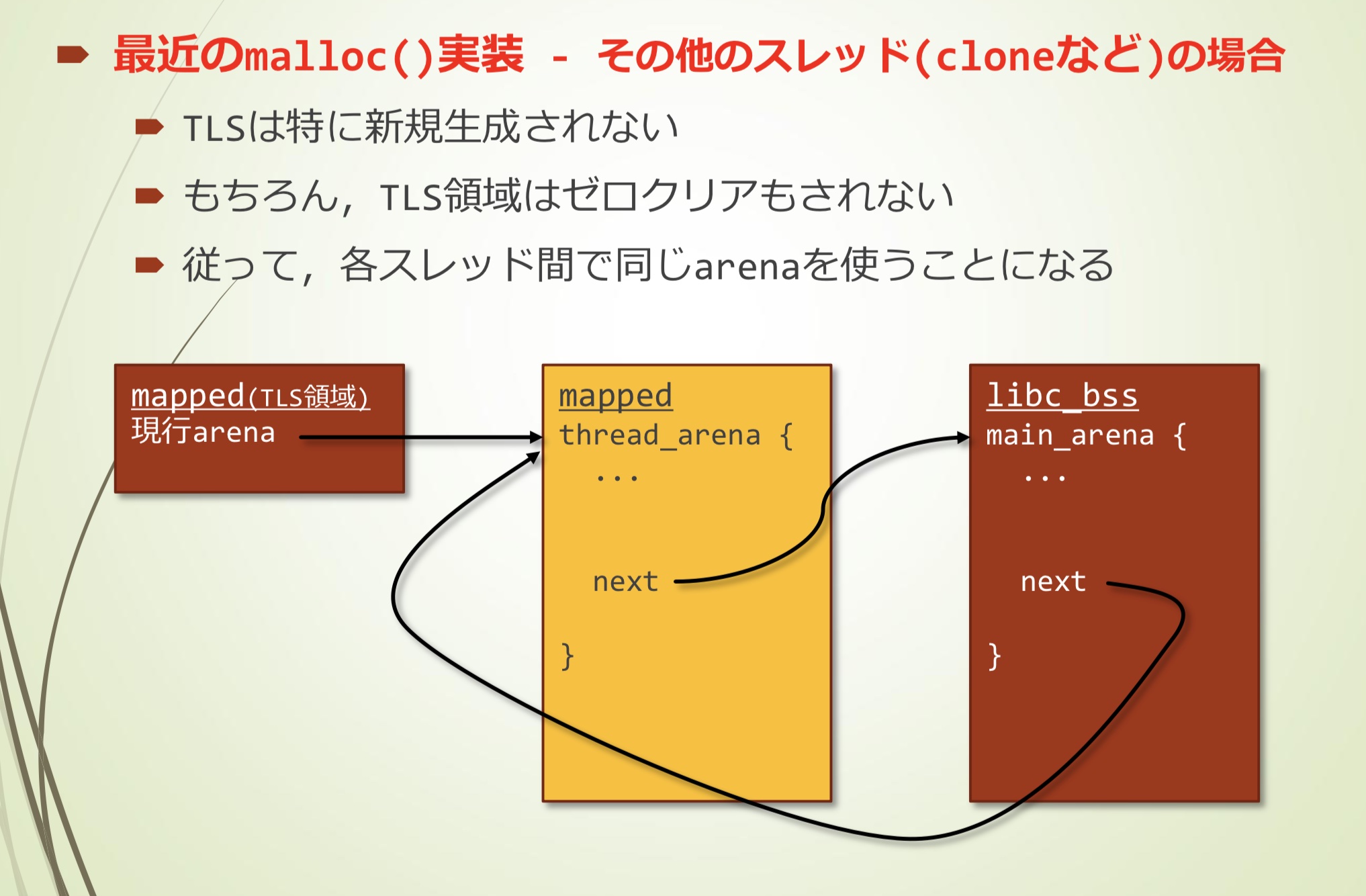
现代malloc()实现 — 其它方式(clone之类)创建多线程的情况
- TLS不是专门新建的
- 当然,TLS区域也不会清零
- 因此,各个线程都使用相同的arena
参考资料
https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
new(-1)
- new(-1)也是类似的情况

- 获取sz参数
- malloc(sz)
- 如果失败,抛出一个std::bad_alloc异常(如果有对应的异常处理程序,则调用它)
- https://gcc.gnu.org/viewcvs/gcc/trunk/libstdc%2B%2B-v3/libsupc%2B%2B/new_op.cc?view=markup
- https://cpplover.blogspot.jp/2010/07/operator-new.html
