优化
Full-Codegen生成的机器代码(半优化代码)的特点
- 生成速度快,运行速度慢(浪费较多)
因此,出现了根据需要进行优化的机制
优化1: 利用类型信息缓存
- 利用Hidden Class的信息,Inline Caching
- 缓存调用的地址和引用的偏移量
- 利用Hidden Class的信息,Inline Caching
优化2: 重新编译为更高效的JIT代码
- 运行时判定优化对象
- 主线程中,正常运行机器代码
- 其他线程中,Runtime-Profiler测定利用情况
- Runtime-Profiler:程序运行时,进行测定,统计的机制
- 基于测定结果,判定是否进行优化
- 使用Crankshaft优化编译
- 再次讲源代码编译为机器代码,替换运行中的机器代码
- 使用TurboFan优化编译
- 再次讲源代码编译为机器代码,替换运行中的机器代码
- 运行时判定优化对象


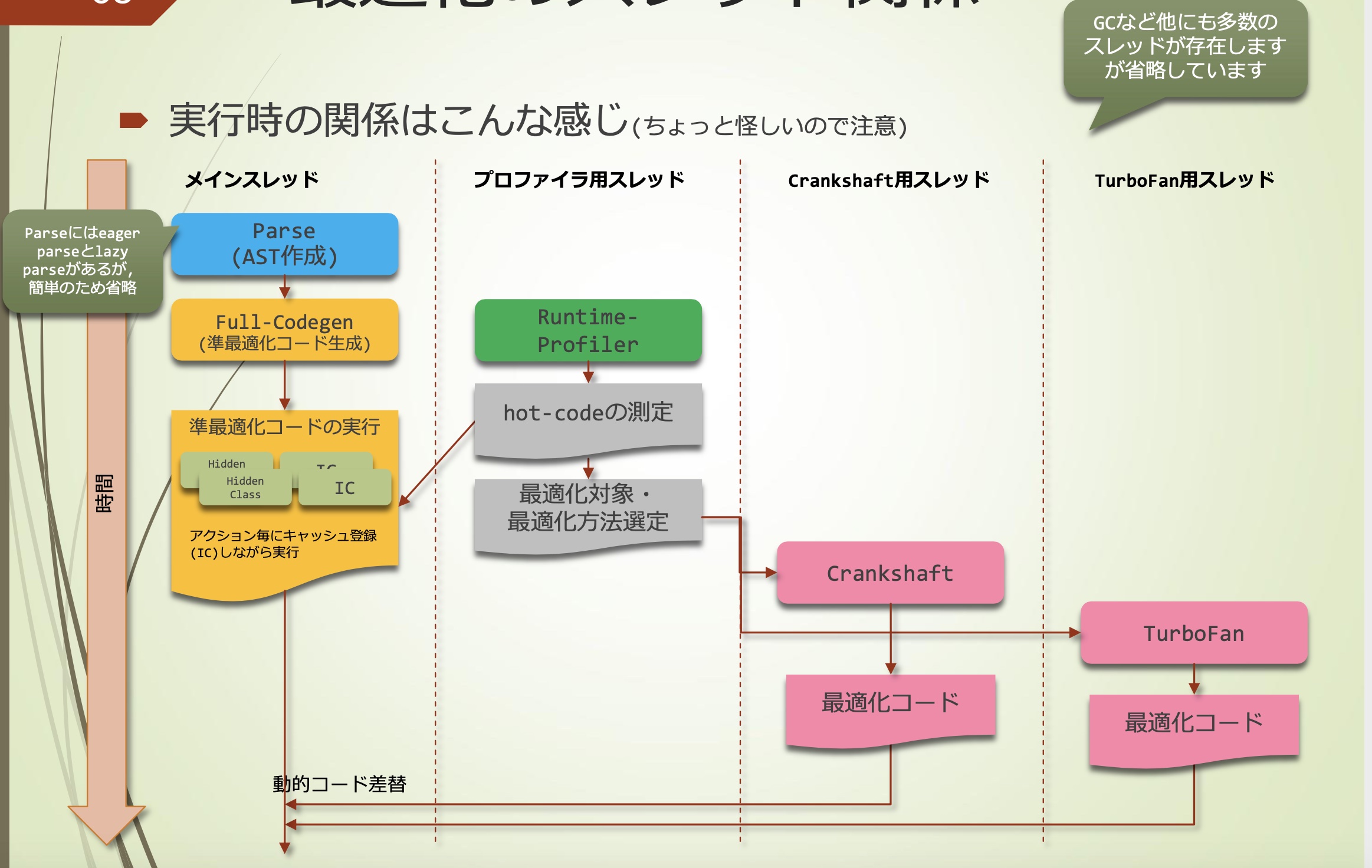
优化的线程关系
运行时的关系大概是这样:
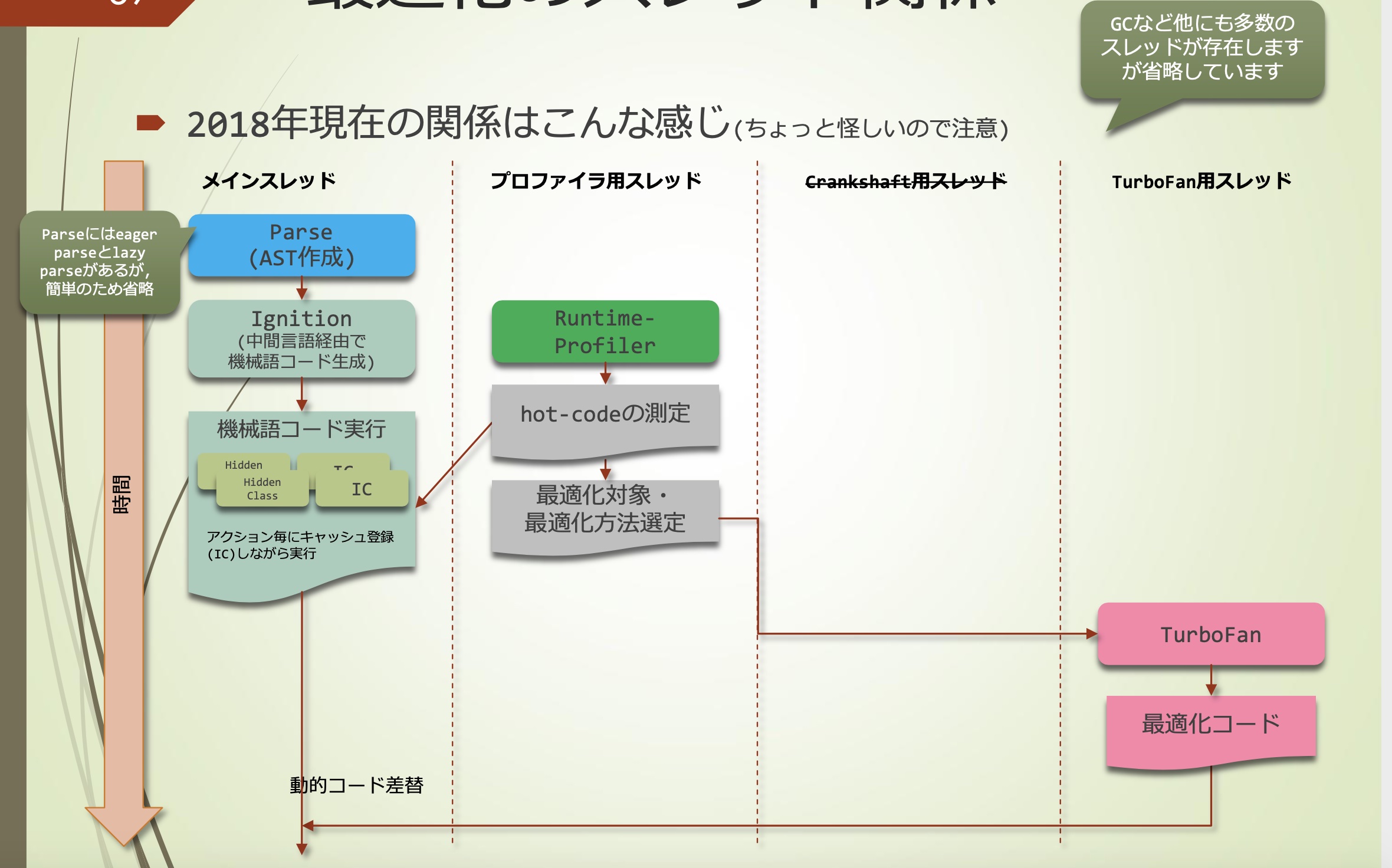
2018年现在的关系大概这样:
2. Hidden Class
Javascript中,Object有property,例如这个例子中,使用函数来实现class,其中有x和y属性,被称为property:

- V8通过调用Hidden Class的机制来实现对property的访问
- 为了高效访问property
- 对property访问的实现
- 一般使用hash table比较多,效率很差
- 直接实现hash table的话,会增加没有使用的浪费掉的区域
- hash冲突情况的处理,管理区域复杂化,也是问题
- hash table和后面要讲的Inline caching的相性不是很好
- 因此需要比hash table更高效的搜索property的机制
- 一般使用hash table比较多,效率很差

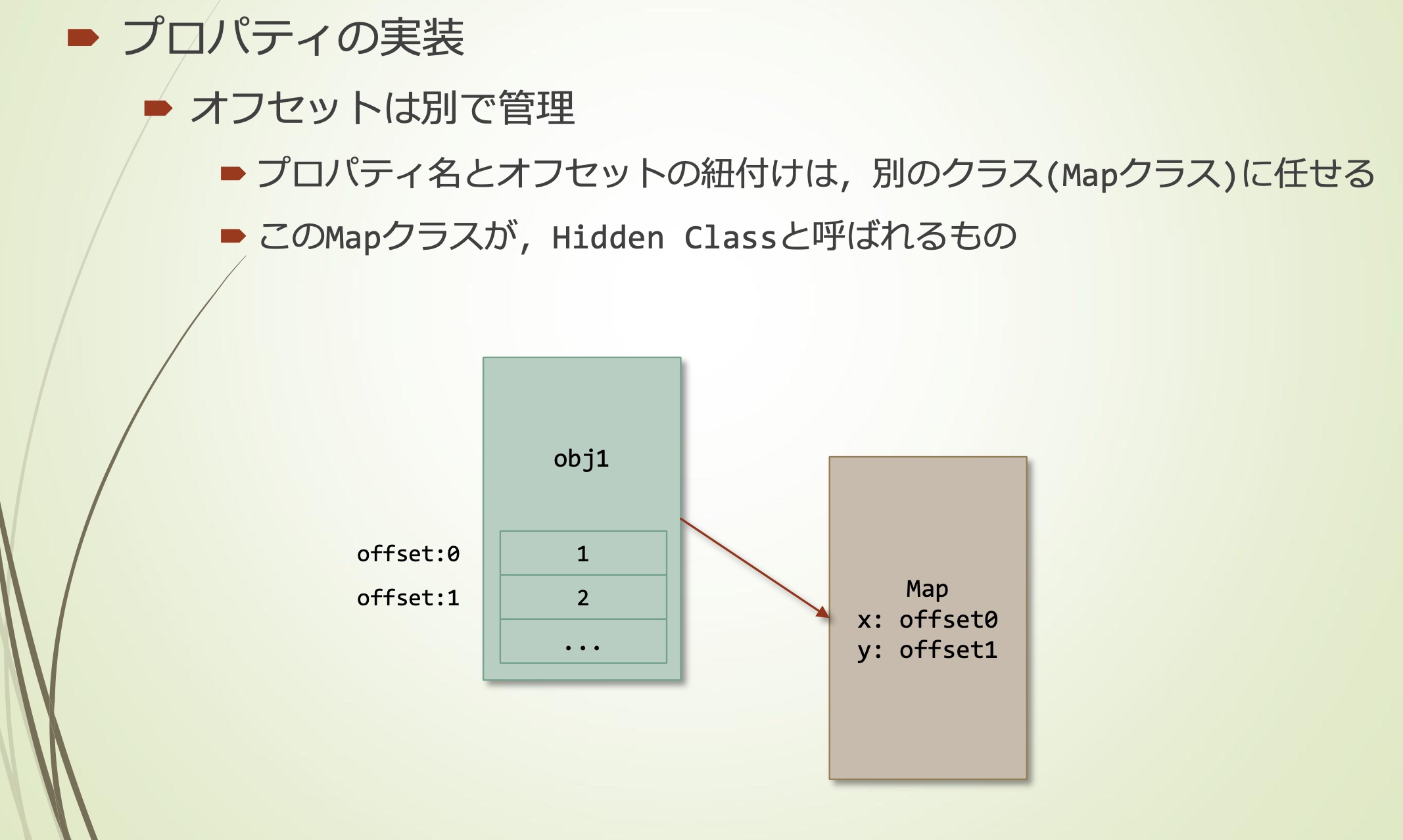
property的实现
- property的值以数组形式进行管理
- 通过偏移值来访问数组中的property值

- offset另外管理
- property名称与偏移量的依赖关系交给别的class(Map)
- 这个Map被称为Hidden Class
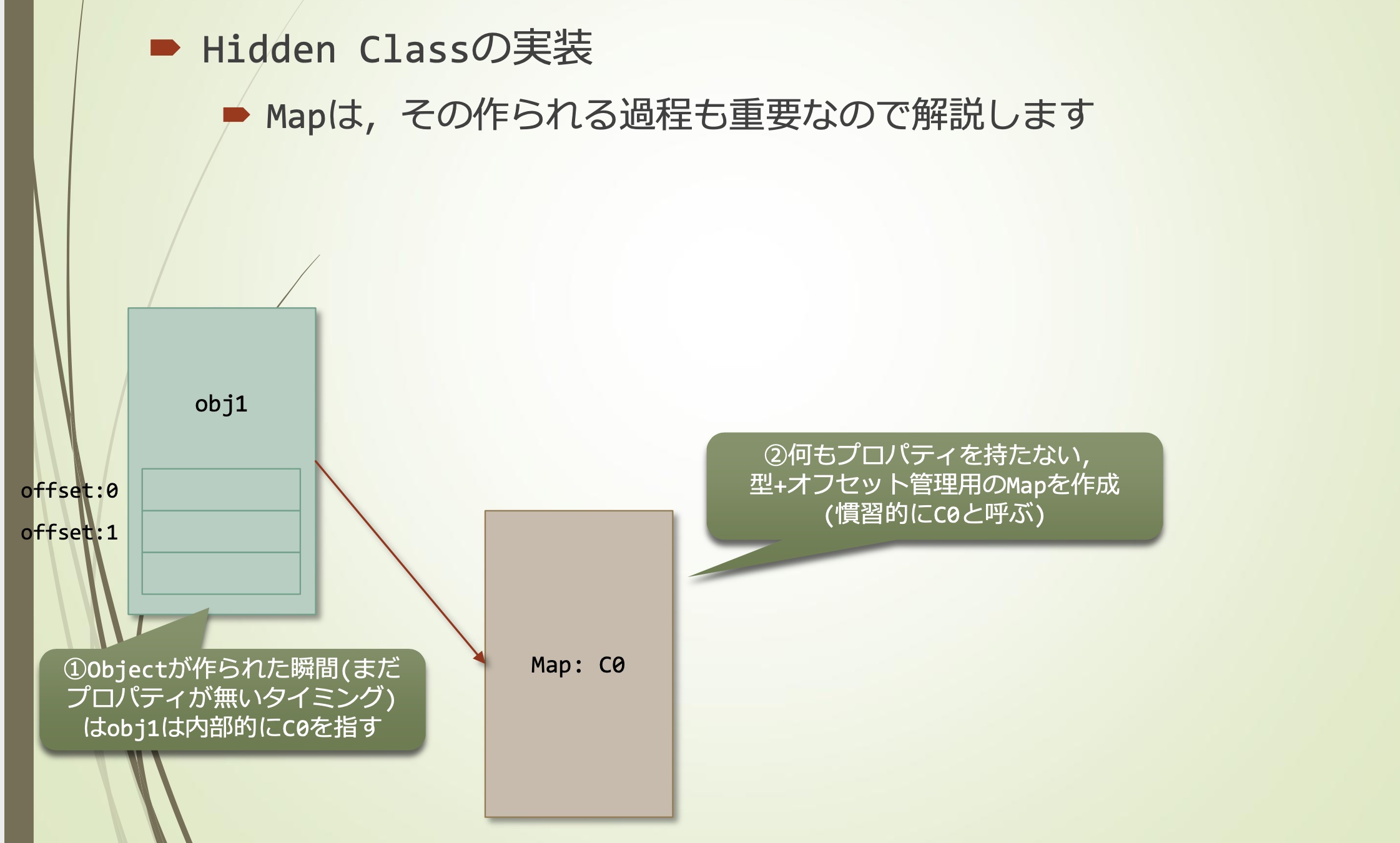
Map
- Object生成时(还没有property时),obj1内部指向C0
- 创建一个没有任何property,用于管理类型和offset的MAP(一般叫C0)
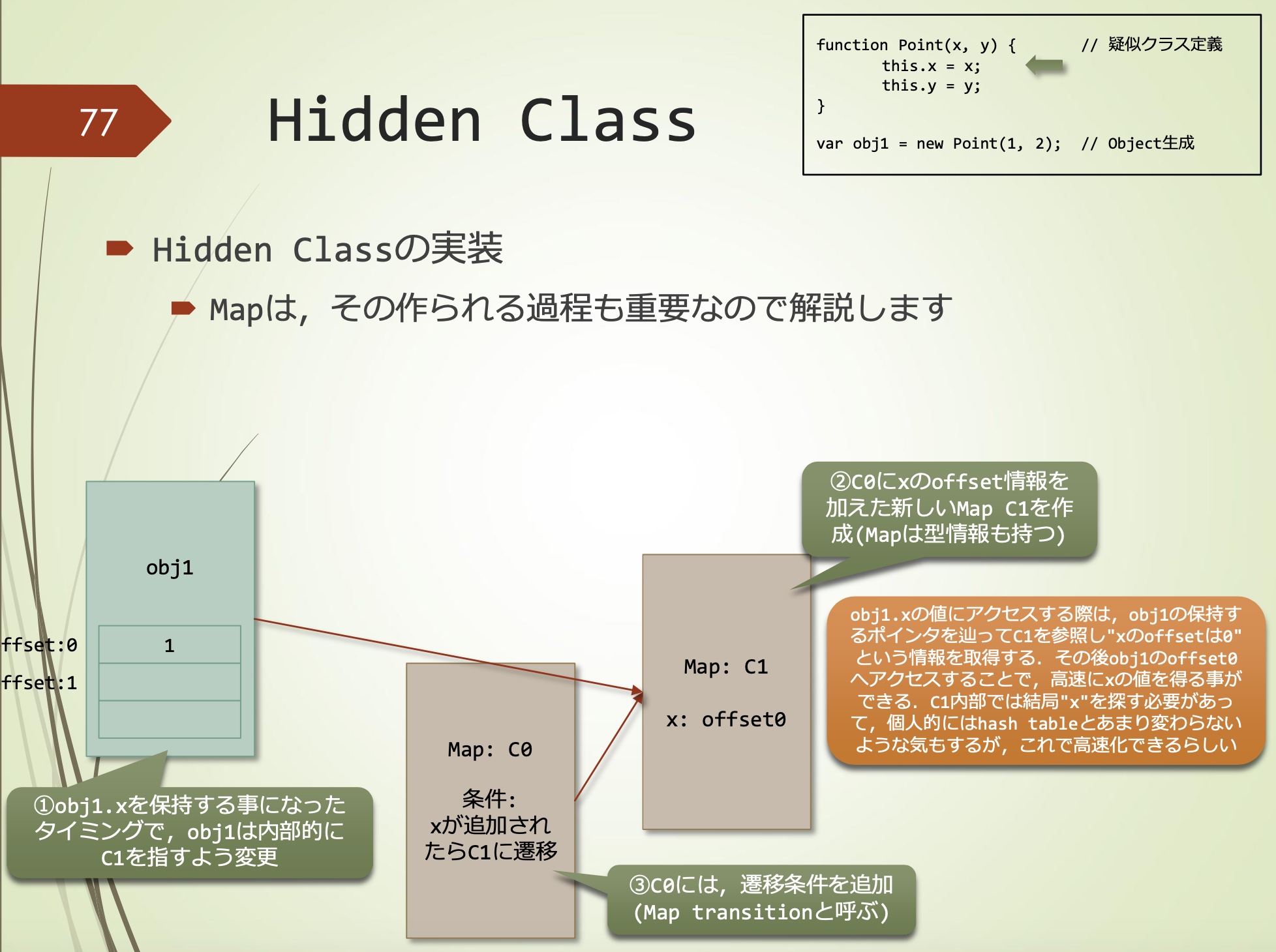
当添加obj1.x时,obj1内部改为指向C1
C0中添加x的offset信息,生成新的Map C1(Map也有类型信息)
C0中添加转移条件(Map transition)
Map C0
条件:当x加入时转移到C1
当访问obj1.x的值时,跟踪obj1所持有的指针,引用C1,获得”x的偏移量为0”的信息。之后,通过访问obj1的偏移量0处的值,可以高速的获得x的值。在C1内部,有必要寻找”x”,尽管我个人觉得它与哈希表似乎没有多大区别,但是这会让它速度更快。
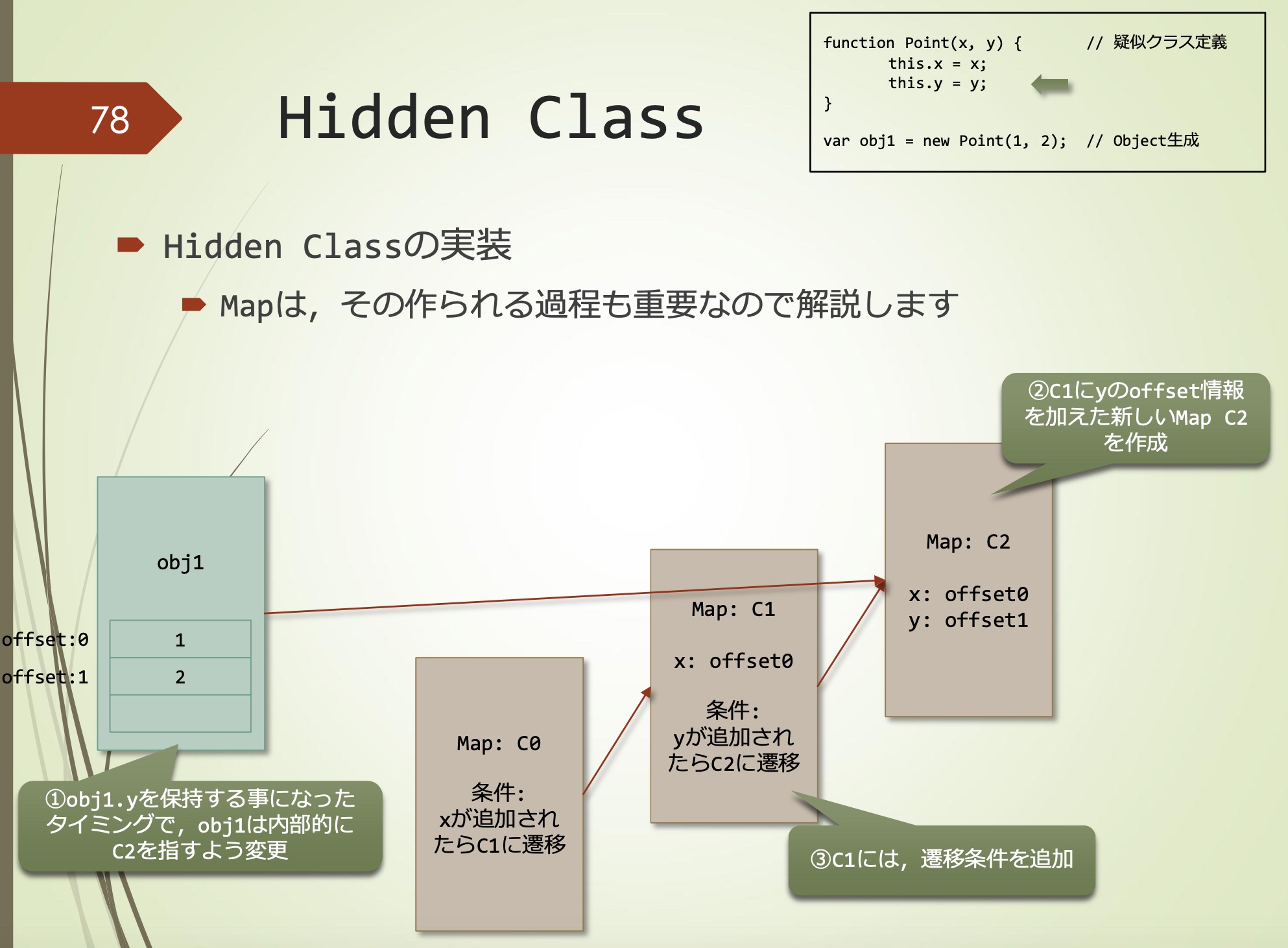
- 当添加obj1.y时,obj1内部改为指向C2
- C1中添加y的offset信息,生成新的Map C2
- C1中添加转移条件
Map C1
条件:当y加入时转换到C2
C0和C1这时候已经不使用了,但后面可能还会用到,随意不会被移除。
Map复用
会存在完全相同property的Object,他们也会有x和y,所以复用生成的Map
创建obj2时指向C0,通过与obj1相同的方式按x和y的顺序添加property,它顺着转换条件以完成C0->C1->C2
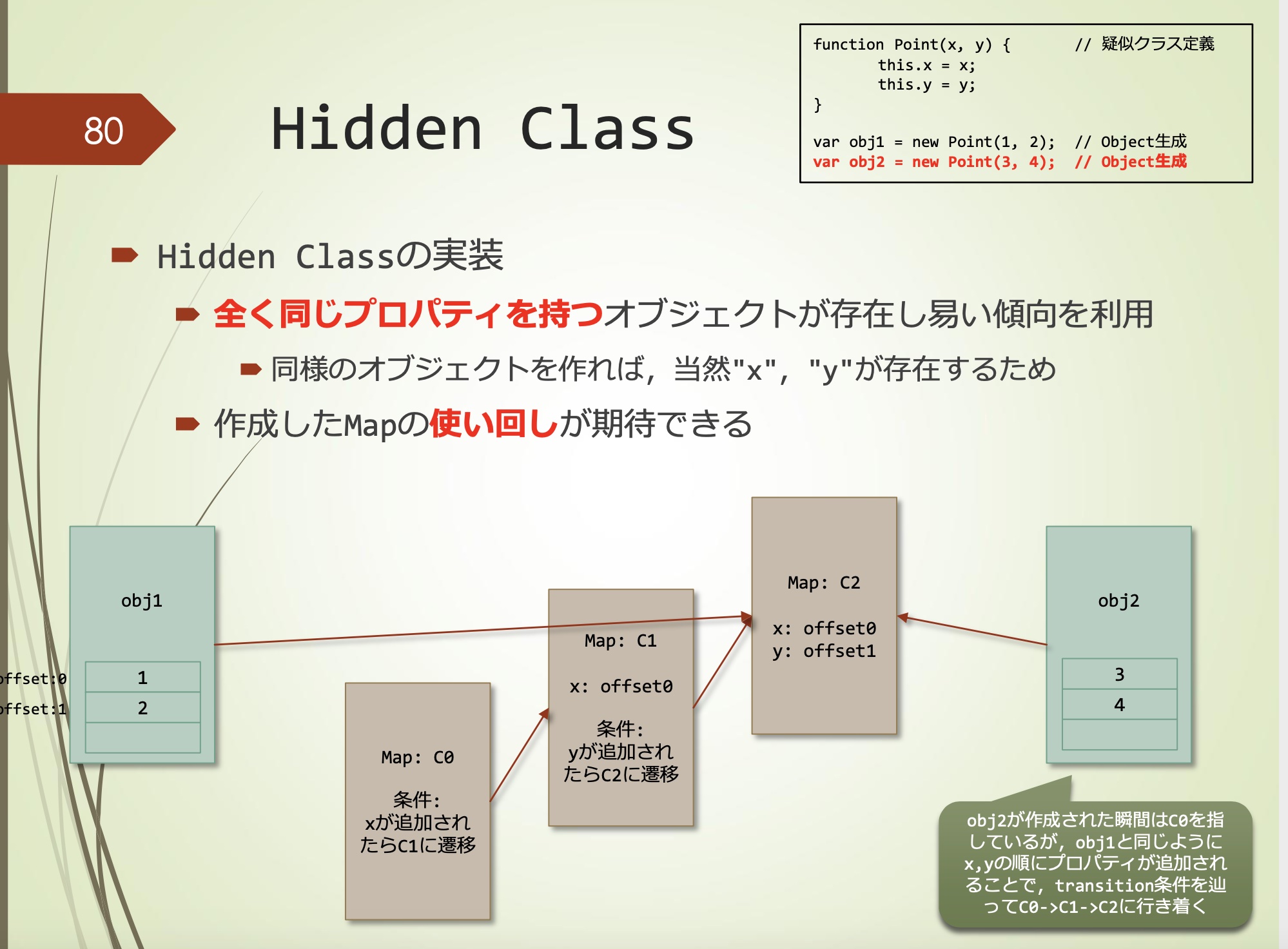
注意:具有相同名称的property的object,如果property的添加循序不同,那么也会具有不同的转换条件。 因此,最终创建的map也会变成不同的map,也就无法享受到获得加速的好处。有关详细信息,请参阅
http://richardartoul.github.io/jekyll/update/2015/04/26/hidden-classes.html
另外,如果property添加/删除次数增加太多,Hidden Class的管理会减慢。因此,这种情况不使用Hidden Class,而使用字典类型来管理
https://v8project.blogspot.jp/2017/08/fast-properties.html
property管理方式
- 默认情况下,property在object内部通过数组管理
- In-Object property
- property增加(超过11个)时,也会使用object外部的数组
- Fast property
- 进一步增加property的话,会使用object外部的字典管理
- Slow/dict property
- 不使用Map,通过外部字典保存所有信息,也别叫做self-contained
- 实体是一个FixedArray的数组,但用法类似下土这种字典
- Slow/dict property

参考:https://v8project.blogspot.jp/2017/08/fast-properties.html
这里想说的
- (javascript的)object中有指向Map的指针
- 后面会说,object开头8个字节是指向Map的指针
- (javascript的)object指向的Map,会根据情况快速改变
- 也就是说,在exploit中,这不是一个能够稳定利用的指针
- 类型相同 = Map的地址相同
- 通过比较Map的地址,可以确定类型的一致性
3. Inline Caching
参考:
- https://blog.ghaiklor.com/optimizations-tricks-in-v8-d284b6c8b183
- https://speakerdeck.com/brn/source-to-binary-journey-of-v8-javascript-engine
- https://www.slideshare.net/ssuser6f246f/v8-javascript-engine-for
- http://cs.au.dk/~jmi/VM/IC-V8.pdf
针对各种action,对类型进行缓存优化的机制
这里说的action,大概是这些:
- 引用,代入(LoadIC, StoreIC)
- 数组访问(KeyedLoadIC, KeyedStoreIC)
- 二项运算(BinaryOpIC) # 最近的V8中好像去掉了?
- 函数调用(CallIC)
- 比较(CompareIC)
- 布尔化(ToBooleanIC) # 最近的V8中好像去掉了?

要考虑到某些action的JIT代码被多次调用
- 循环和函数之类的,多次传递相同的JIT代码
执行JIT代码时,关注操作对象(≒参数)的类型
- JIT代码,有较高的可能性和上次时同样类型的操作
- 例如下面的Javascript代码,明显是重复相同类型的操作
- 对应到JIT代码,也同样成立

JavaScript类型,等价于map地址
- 从 Hidden Class的实现可以知道,同样类型的话,Map地址也是相同的
- 对类型进行缓存,也就是将map地址嵌入到JIT code中
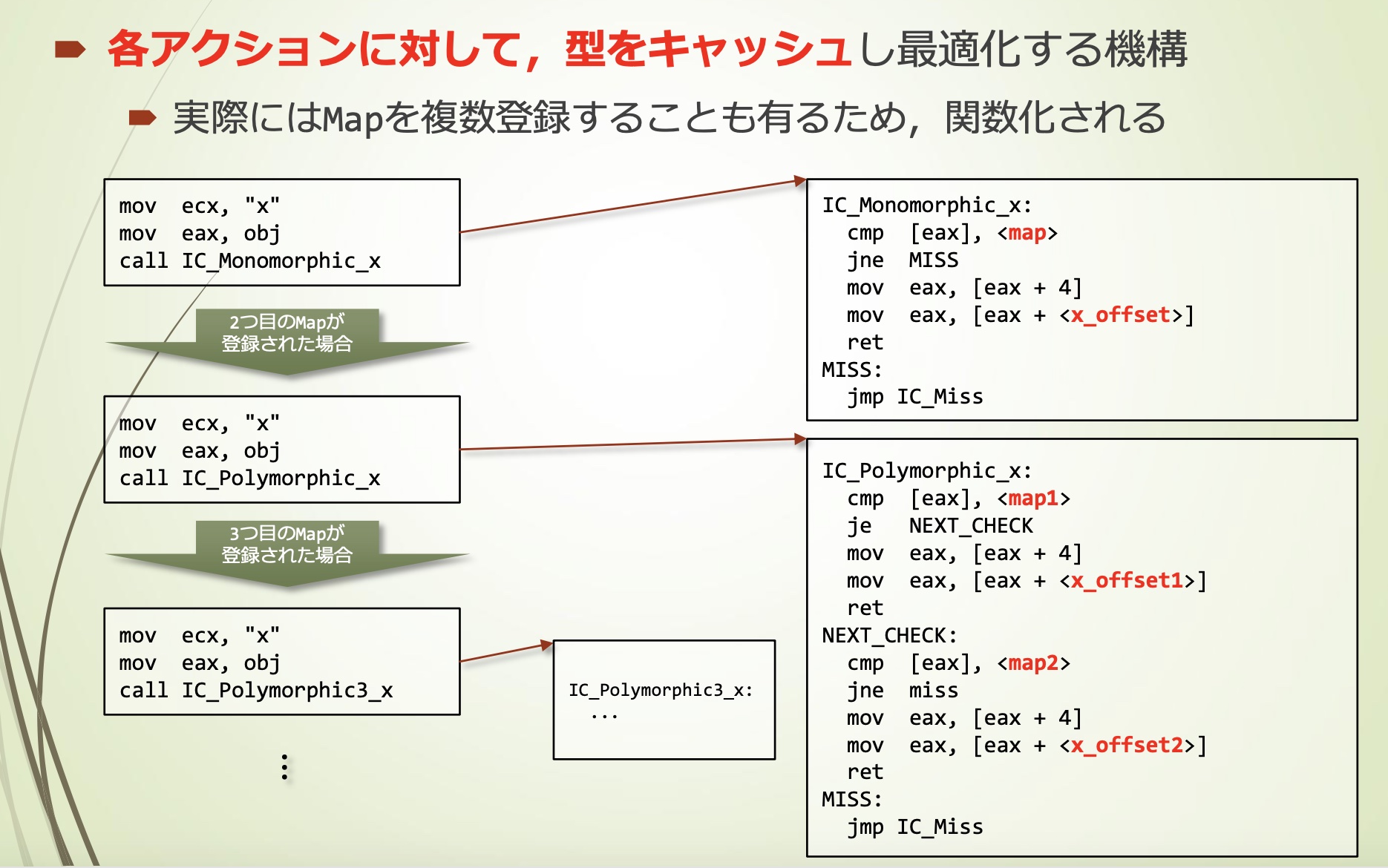
- 例如对obj.x进行引用(Load)的IC,大概是这样:
- x的offset也一起缓存
- 当Map匹配时,通过x的offset得到property x,然后返回

实际上会有多个Map注册的情况,因此进行函数化
IC持有State
UNINITIALIZED(0): 未初始化
PREMONOMORPHIC(.): 当前只被执行过一次,还没进行IC
MONOMORPHIC(1): 只注册一个IC的情况(快速)
POLYMORPHIC(P): 注册多个IC的情况(一般速度)
MEGAMORPHIC(N): 注册很多个IC的情况(慢速)
GENERIC(G): IC已停止的状态
括号里是后面说的debug输出(–trace-ic)的省略的标注
基本上是按照从上到下(0->.->1->P->N->G)的顺序迁移
- CallIC之类的,是直接0->1

Inline Caching,可以使用–trace-ic确认
–use-ic使IC有效化(默认),–no-use-ic使IC无效
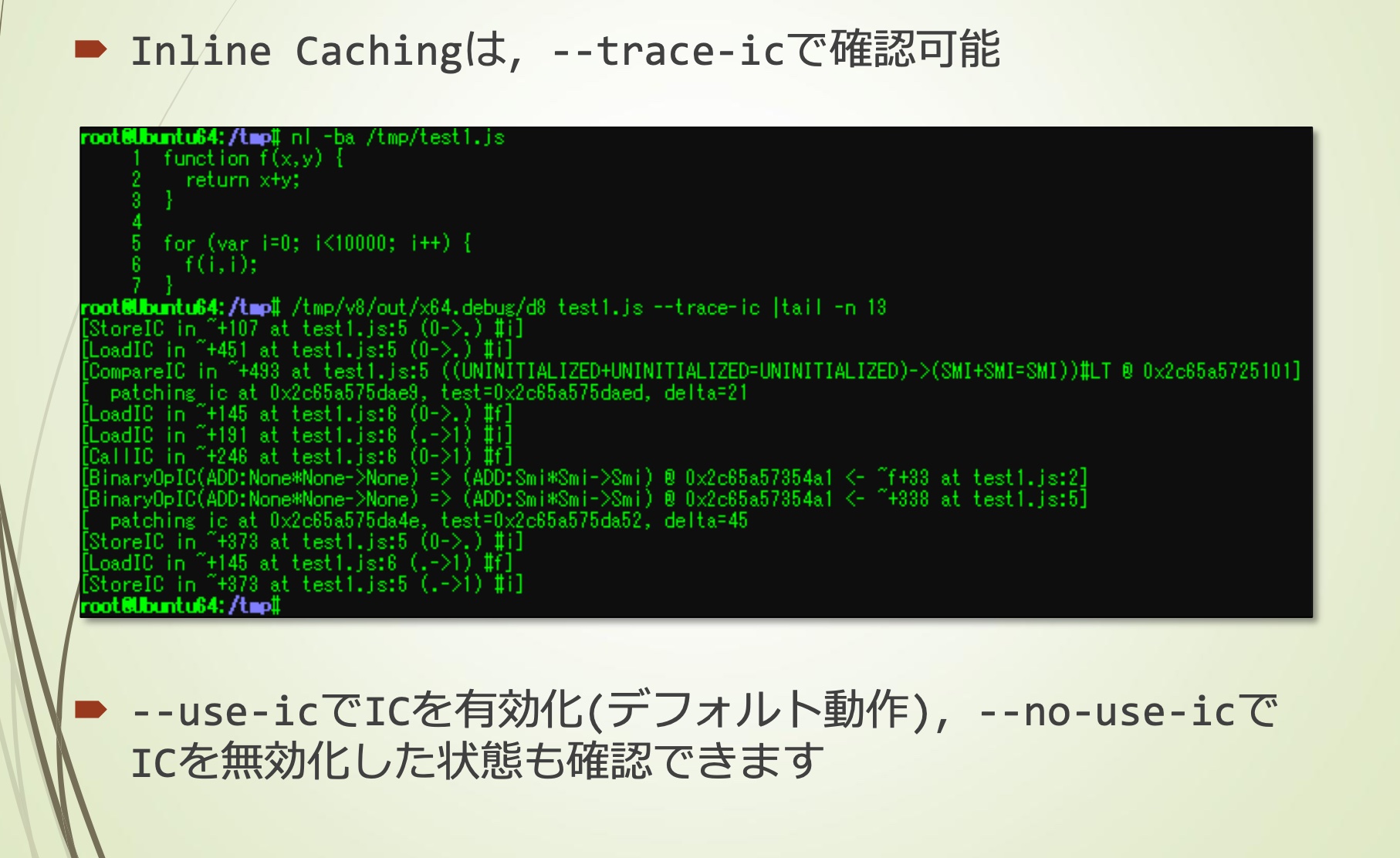
关于Inline Caching
对前面的总结:
- 与Hidden Class配对,对高速化做出巨大贡献
- 对于exploit,只需要关注地址和偏移在JIT中的缓存
- 创建任意地址读写的原语比较难,因此与exploit的相性不好
- 但是,某些情况下,IC执行的部分检查(例如边界检查)被部分简化
- 也就存在在非IC下不会引发的漏洞可能会在IC下触发
